前幾天火爆的Kolmogorov-Arnold Networks是具有開創性,目前整個人工智能社區都只關注一件事LLM。我們很少看到有挑戰人工智能基本原理的論文了,但這篇論文給了我們新的方向。
mlp或多層感知位于AI架構的最底部,幾乎是每個深度學習架構的一部分。而KAN直接挑戰了這一基礎,並且也挑戰了這些模型的黑箱性質。
也許你看到了很多關于KAN的報告,但是裏面只是簡單的描述性介紹,對于他的運行原理還是不清楚,所以我們這篇文章將涉及大量的數學知識,主要介紹KAN背後的數學原理。
KANKolmogorov-Arnold Networks引入了一種基于Kolmogorov-Arnold表示定理的新型神經網絡架構,爲傳統的多層感知器(mlp)提供了一種有前途的替代方案。
mlp在節點(“神經元”)上有固定的激活函數,而kan在邊緣(“權重”)上有可學習的激活函數。kan根本沒有線性權重,每個權重參數都被參數化爲樣條的單變量函數。這個看似簡單的改變使得KANs在准確性和可解釋性方面優于mlp。KANs是mlp的有希望的替代品,爲進一步改進當今嚴重依賴mlp的深度學習模型提供了機會。
上面論文的原文,根據論文在數據擬合和PDE求解方面,更小的kan與更大的mlp相當或更好。所以kan可能比mlp擁有更快的神經縮放定律。並且KANs可以直觀地可視化,大大提高了可解釋性。

論文圍繞函數逼近的Kolmogorov-Arnold表示定理的性質展開,這是這篇論文的全部前提。
表示定理基礎:函數被分解成更簡單的函數,然後使用神經網絡進行近似。
平滑性和連續性:目標是確保原始多元函數的平滑性有效地轉化爲神經網絡近似。
空間填充曲線:函數跨維度的屬性,特別是關注在近似過程中如何保持連續性和其他函數屬性或轉換。
什麽是樣條?爲什麽KAN需要樣條?上面進行了簡單的介紹,下面我們開始深入理解論文的數學基礎,這是其他報道中沒有的。
樣條是一種數學函數,用于通過一組控制點創建光滑和靈活的曲線或曲面。在數學術語中,樣條是一個分段多項式函數,它在多項式塊相交的地方(結點)保持高度平滑。

樣條有幾種類型,包括:
線性樣條:用直線連接點,簡單但不流暢。這在點上是不可微的。
二次和三次樣條:二次或三次多項式創建曲線。三次樣條曲線被廣泛使用,因爲它在靈活性和計算複雜性之間提供了很好的平衡。
b樣條(基樣條):對曲線形狀提供更好的控制,特別是在邊界附近,並在一組控制點上定義,這些控制點不一定位于曲線本身。
論文則是將b樣條用于kan:與基本樣條不同,b樣條不一定通過其控制點。而是通過這些點從遠處引導曲線的形狀,提供了一種更靈活的方式來描述複雜的形狀和圖案。
b樣條在kan中特別有用,因爲它們在處理高維數據時具有魯棒性,並且能夠形成光滑的多維表面。對于神經網絡,在高維數據中學習是標准的,b樣條可以用來管理模型的複雜性,並且持計算效率,同時不會失去可解釋性。
Kolmogorov-Arnold表示定理Kolmogorov-Arnold表示定理背後的核心思想是,任何(多變量)連續函數都可以表示爲單變量連續函數和加法運算的組合。無論多變量函數看起來多麽複雜,都可以用更簡單的單變量函數來表示它。它和傅裏葉級數很相似,傅裏葉級數是一個連續的周期函數由諧波相關正弦函數的和生成。
下面是Kolmogorov-Arnold表示定理的數學公式:

該定理提供了一種將複雜的多變量函數分解爲每次只涉及一個變量的一系列操作的方法,使其更容易理解和計算。這在神經網絡等環境中這種分解可以幫助設計架構,使用更簡單、更容易訓練的組件有效地近似複雜函數。
KAN的數學原理1、傳統MLP層
我們先來看看MLP。mlp基于普遍逼近定理,該定理指出,在對激活函數的溫和假設下,具有單個隱藏層的前饋網絡包含有限數量的神經元,可以在𝑅_𝑛的緊湊子集上近似連續函數。

這裏的𝜎爲固定非線性激活函數,𝑤爲權重,𝑏爲偏差,𝑎爲輸出權重。
在典型的mlp中,每一層由一個線性變換和一個非線性激活函數組成。這意味著對于任何給定的輸入,網絡計算輸入的加權和,然後應用一個非線性函數,如ReLU, sigmoid等。這樣mlp對許多任務都是有效的,但可能受到其轉換的固定性質和參數變化的全局影響的限制。

2、KAN層
與標准的線性加非線性方法不同,KAN層使用一維函數矩陣(例如b樣條),其中連續層中兩個節點之間的每個連接都由一個可以單獨調整的單獨函數定義。
這種結構爲函數逼近過程提供了更高程度的靈活性和局部控制。每個連接學習從輸入到輸出的整體特征映射的特定部分,這可能導致對數據的更細致的理解和表示。
具有n維輸入和無維輸出的KAN層可以定義爲一維函數的矩陣。

KAN層定義爲一維函數𝜙_𝑝的矩陣Φ,𝑞中𝑝表示輸入維度,q表示輸出維度。每個函數𝜙_𝑝,𝑞都有可訓練的參數,並將輸入直接映射到輸出,而不需要中間的加權和和之後的通用激活。
KANs結構:
與mlp不同,KAN層中的每個連接都由單個1D函數𝜙_𝑙,𝑗,定義,該函數直接將輸入映射到輸出(l是第l層)。這種體系結構不需要矩陣乘法,而是使用一組函數映射,其中每個函數負責將輸入的一個組件轉換爲輸出的一個組件。
整個層可以被描述爲這些函數的矩陣Φ,其中每個函數𝜙_𝑙,𝑗,直接從每個輸入節點𝑖應用到每個輸出節點𝑗。這種設置爲數據轉換提供了更靈活和定制的方法:
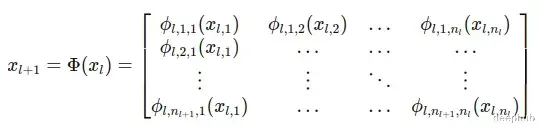
KANs的基礎是基于一個監督學習任務,其目標是近似一個函數𝑓,該函數將所有數據點的輸入𝑥部關系映射到輸出𝑦部關系。該方法使用Kolmogorov-Arnold定理將任意多元函數分解爲一系列單變量函數和求和運算:

方程表明,對于每個輸入維度𝑥_𝑝,都有一個單變量函數𝜙_𝑞,𝑝和Φ_𝑞是聚合這些單變量函數輸出的高級函數。
如果我們展開上面的方程:

爲了理解這些他們的不同之處,我們舉一個簡單的例子,比較KAN和MLP的輸出。如果的從上面的數學原理看有點複雜,所以讓我們寫一個更簡單的版本和MLP對比就更容易理解最後發生了什麽。
1、MLP

讓我們假設以下配置和值:
Input Layer: 3
Hidden Layer 1: 4
Hidden Layer 2: 2
Output Layer: 1
權重矩陣:

輸入

MLP的計算如下:

2、KAN

輸入
KAN的計算如下:

在MLP中,每個層執行一個加權和,然後是一個非線性激活函數,而在KAN中,每個“連接”應用一個特定的函數(我們在本例中使用隨機函數),並將這些函數輸出聚合爲前饋。

3、對比總結
MLP:矩陣乘法是根據權重調整的線性變換。非線性(本例中的ReLU)允許網絡模擬非線性現象。
KAN:每個節點連接應用b樣條或其他定義函數,使其高度靈活,並根據每個輸入特征所需的特定轉換進行定制。
總結在更少參數的情況下,kan可以達到與mlp相當甚至更高的精度。由于其架構,KAN還提供了增強的可解釋性,其中每個權重都被參數化爲樣條的可學習單變量函數所取代。論文強調了基于Kolmogorov-Arnold表示定理的KANs的數學優雅性,該定理爲這些網絡提供了強大的理論基礎。
KAN這篇論文確實很大,而且涉及了更多的細節,我還在進行更深入的研究,並且我自己的測試與mlp相比它們需要更少的訓練樣本,但是KAN的擬合速度沒有MLP快,而且最終得到的效果我還沒有看到比MLP好多少,所以具體是否好用我還在更詳細的測試。
但是無論如何KAN爲人工智能社區帶來了一股新鮮空氣,這是非常值得稱贊和尊重的。
https://avoid.overfit.cn/post/6ee2307e614b462f9c9aac26ef12252d
作者:Vishal Rajput
