引言:AI與大模型風起雲湧,爲什麽催生了這匹存儲“黑馬”?

【阿明觀察 | 科技熱點關注】
這家總部設在美國的存儲初創公司,真的趕上AI與大模型時代的風口了。Vast Data公司最新再次獲得E輪融資1.18億美元,但是這個存儲公司融來的資金還沒想好怎麽用,現在只是和之前ABCD輪融資一道存銀行吃利息而已。你是不是被震驚到了?
目前VAST Data該E輪已經籌集了1.18億美元的新資金,由 Fidelity Ventures 領投,New Enterprise Associates、BOND Capital、Drive Capital、Nvidia、Dell Technologies Capital、高盛、Tiger Global、Commonfund、Norwest、83North、Greenfield和Next47跟投。估值爲91億美元,ABCDE輪籌集的現金總額達到3.81億美元,約合人民幣27.3億元。
查閱已經被公開的資料發現,VAST Data天使輪融資0.15億美元,A輪融資0.25億美元,B輪融資0.4億美元,C輪融資1億美元,D輪0.83億美元。其中Dell Technologies Capital在ABCDE五輪融資中都有參與。
VAST Data公司在全球擁有700多名員工,2016年,Renen Hallak與Jeff Denworth、曾在Kaminario和IBM擔任領導職務的Shachar Fienblit和曾在Cisco和IBM擔任領導職務的Alon Horev共同在美國紐約創立。

VAST Data通過使用底層QLC閃存,結合由SCM類型的SSD加速,同時關鍵的是在于分離了控制器和存儲節點,並提供對文件和對象數據的並行橫向擴展訪問。最終實現了利用商用服務器硬件,爲人工智能工作負載提供對大規模的數據集的更快訪問。
Vast將存儲、數據庫和計算引擎服務統一在一個平台中,爲跨數據中心和雲的AI應用,以及GPU工作負載加速提供能力支持。
這樣也就爲用戶省去了找一個集成商去整合NAS解決方案、對象存儲、並行文件系統和數據倉庫等構件一個複雜方案。麥肯錫(McKinsey)的數據顯示,生成式AI預計將爲全球經濟創造2至4萬億美元市場價值,而其中GPU將爲此提供大部分價值。VAST Data統一數據平台,可以爲用戶在AIGC應用上省錢,這個事情確實很吸引人。
爲此,前幾天,GPU雲服務商CoreWeave的首席執行官兼聯合創始人Michael Intrator表示,通過與VAST Data合作,能夠使設施比傳統雲基礎設施快35倍,成本低80%。如此看來,VAST Data公司的産業生態也逐漸在打開了。
值得一提的是,VAST Data平台已經通過Nvidia GPU Direct訪問認證,並在其上構建了數據目錄和數據庫,以及即將推出的數據引擎,該引擎承諾使人工智能流程能夠發現其所分析數據的新見解。隨著人工智能不斷被大肆宣傳,也就成爲了VAST Data籌集風投資金的好時機。
值得注意的是,VAST表示,這筆資金將推進其使命,提供一個新的基礎設施類別,將數據放在系統工作的中心。目前還沒有關于這些現金將如何實際使用的細節。
事實上,VAST Data聯合創始人Jeff Denworth說:"這筆資金只是被用來提高人們對VAST和我們使命的認識。 VAST現在的現金流非常順暢,業務拓展也很有建樹。我們已經成功地建立了一個公司,它可以每年增加三倍的業務量,而不用燒掉堆積如山的風險投資。這筆新的E輪融資將與我們從B輪、C輪和D輪融資中獲得的資金一起存在銀行並收取利息。"
如此說來,除去天使輪與A輪的0.4億美元融資,其他融資總共有3.41億美元,約合人民幣24.4億元。
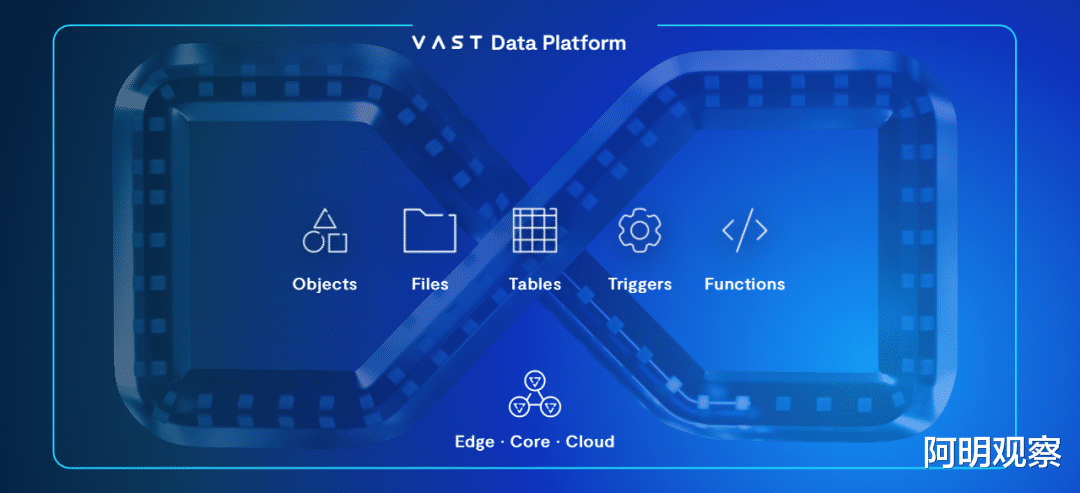
現在的VAST Data Universal Storage 5.0能力更爲強大,針對在雲方面的融合能力,VAST DataSpace擁有多集群管理器、快照、複制等技術功能,簡化用戶的雲部署,目前可以看到Vast Data與亞馬遜雲科技AWS的對接。

針對AI與大模型訓練等以性能爲中心的應用場景而言,Vast Data強調爲用戶提供更細粒度的QoS保障,采用全新的用戶級控制爲每個使用者行爲設置了護欄,並利用人工智能特別是深度學習的能力,監控存儲系統中使用者的行爲,並且可以限定任何一位高級用戶可能破壞其他人的數據訪問體驗。
Vast Data的現任CMO Marianne Budnik表示,在不到一年的時間裏,新一代人工智能重塑了數據基礎設施的格局,並對高度可擴展、高性能和安全的系統提出了新的要求,這些系統可以應對大型語言模型帶來的獨特挑戰。新的專用雲已經形成,以滿足人工智能特定的用例。企業越來越專注于構建AIGC相關應用並更好支持客戶發展。
在2022年11月ChatGPT推出後,大多數組織今天正在探索生成性人工智能用例,許多組織正在進行重大投資。由于人工智能應用程序旨在從大量數據中提取見解,因此它們需要具有最高規模和性能的基礎設施。
人工智能計算下一個時代的基礎只能通過解決以前阻礙人工智能應用進行實時數據處理和學習的基本基礎設施權衡來建立。對于非結構化數據存儲,這意味著以文件和對象存儲的VAST DataStore模式已經打破性能和容量之間的權衡。
通過VAST DataStore,可以擺脫存儲分層複雜性,成爲企業人工智能就緒的非結構化數據存儲的基礎,甚至VAST也成爲了HPE GreenLake文件存儲背後的軟件。
業界的評價還是很有亮點,VAST Data成爲了用于生成AI的最有效的存儲平台,可以容納多個訪問協議,並獨立擴展性能和容量,允許按需性能靈活性和長期成本效益。VAST自第一天起就一直在爲人工智能計算奠定基礎,這是一個可以匹配人工智能時代公司雄心壯志的數據平台。而今,VAST Data連續第二年被認定爲2023年Gartner分布式文件系統和對象存儲魔力象限™的挑戰者。

不過,這裏再說一下核心能力。Vast Data核心能力源自DASE分布式創新架構。
在20年前,谷歌推出無共享系統(shared-nothing)的想法帶來了存儲領域的革命,分布式存儲從而走向了曆史舞台。20年後,VAST構建了DASE系統,旨在打破分布式系統的傳統擴展限制。
DASE架構將計算邏輯與系統狀態解耦,並引入了新的共享和事務數據結構,這些設計結合在一起爲下一代人工智能注入計算奠定了基礎。
DASE將容量與性能、數據與豐富的元數據、邊緣與雲、簡單與規模相結合。以前相互排斥的數據和系統概念現在“未來架構”的平台上和諧共存。
然而,深度學習和數據存儲平台之間的鴻溝現在清晰而存在。爲什麽今天的數據存儲平台不能滿足現代深度學習的需求?
從根本上說,這些系統並非旨在存儲和處理AI應用的豐富數據類型。今天流行的數據存儲平台是爲現代化業務發展而設計,而不是爲人工智能而設計。事實上,如果深度學習從未存在,今天數據存儲平台的采用將保持不變,因爲這些系統主要側重于塊存儲數據。雖然這些系統已經過改造,以解決機器學習和深度學習用例的某些需求,但差距仍然存在。

與基于批處理的計算架構不同,VAST架構利用實時寫入緩存區,並在流入系統時實時捕獲和操作數據。該緩存區可以攔截小型隨機寫入操作或大規模並行寫入操作到持久內存空間,小型隨機寫入操作如事件流或數據庫條目,大規模並行寫入操作如應用程序檢查點文件創建。
借助該內存空間可以立即與主存儲如基于閃存的相對更低成本超大規模存檔存儲中的其他系統語料庫進行檢索和相關分析。因此,Vast Data平台專注于深度學習,致力于從非結構化數據中進行存儲並支撐大模型數據檢索與分析。
因此,說來說去,Vast Data爲深度學習以及大模型訓練帶來了更友好的數據存儲平台支撐,自然更容易被新的應用所采納,被資本所看好。

其實,在針對AI領域蓬勃發展的背後,對AI相關存儲支持的專注也有大廠的參與,比如老將IBM也將IBM Storage Scale、IBM Storage Scale System、IBM Cloud Object Storage和IBM Storage Ceph多個軟件整合在一起,建構了IBM的全球數據平台Global Data Platform,看著這名字就覺得大氣,不愧是久經沙場的老手。
因此,在面向AI發展的存儲基礎設施創新之路上,Vast Data的對手還有不少的,回頭有時間,阿明再和大家梳理梳理。
新老玩家都在努力,Vast Data可不要太傲嬌哦。
- END-
你
怎
麽
看
?
歡迎文末評論補充!
【科技明說|全球雲觀察|全球存儲觀察 |阿明觀察】專注科技公司分析,用數據說話,帶你看懂科技。本文和作者回複僅代表個人觀點,不構成任何投資建議。

後面不要看就知道 吃利息就可以了