
前幾天,世超上網沖浪的時候,刷到了幾個 AI 視頻片段。
大船駛來的壓迫感,被風吹起的發絲和絲巾,太空人直接走進現實菜園。。。一幕幕把我看得是一愣一愣的。

真實度也是一絕,在湖邊隨著鏡頭移動,不僅光線跟著變化,連天空、樹木的變化都跟咱肉眼看到的沒差。

要不是右下角有水印,我還差點以爲是 Sora 的視頻又上新了。
所以這次的主角不是 Sora ,也不是各位差友熟知的 Pika 、 Runway 那幾個 Sora 競品,而是初出茅廬的國産視頻大模型 Vidu。
咱看到的那些視頻,就是前幾天, Vidu 在中關村論壇的人工智能主題日上公布的。
它最長能生成16 秒,一句 “ 木頭玩具船在地毯上航行 ” 的提示詞,就能生成下面這長長的一段,一鏡到底的絲滑程度,怕是路過的謀子導演看了都會點贊。

Sora 號稱能真實模擬物理世界的拿手戲, Vidu 照樣也能實現。
讓它生成一段 “ 汽車加速駛過森林裏鄉間小路 ” 的視頻,像是樹林縫隙透過的陽光,後輪揚起的灰塵,都很符合咱們的日常認知。

而且 Vidu 的想象力比咱人還要豐富,畫室裏的一艘船駛向鏡頭的場景,它分分鍾就能給 “ 拍 ” 出來,看這效果,不知道該有多少動效師瑟瑟發抖了。

甚至在某些提示詞下, Vidu 的理解能力比 Sora 還強,比如 “ 鏡頭繞著電視旋轉 ” 的提示詞, Sora 壓根兒就沒 get 到旋轉的意思,反而是 Vidu 能輕松理解。

有一說一,在看完 Vidu 的這些視頻後,世超是真覺得它是目前市面上,唯一一個能在畫面效果上和 Sora 拼一拼的模型。
雖然現在16 秒的 Vidu在時長上還比不上60 秒的 Sora,但它的進步也確實是肉眼可見的快,據極客公園消息,上個月, Vidu 在內部只能生成 8 秒的視頻,上上上個月,還只能生成 4 秒的視頻。

反正媒體們都把 Vidu 比作是 “ Sora 級視頻大模型 ” ,網友們也都在評論區喊話催他們趕緊開放內測。

不過這裏面世超更好奇的是,咱之前壓根兒都沒聽說過 Vidu ,怎麽突然平地一聲雷,搞出了這麽大的陣仗?
我們也順藤摸瓜找了找資料,發現 Vidu 身上,值得說道的東西還挺多,甚至仔細咂摸下,還能從 Sora 身上找出點 Vidu 的影子來( 世超可沒說反 )。

它背後是一家名叫生數科技的公司,別看這個公司才剛滿一周歲,但它可是在娘胎裏就開始攢勁兒了。因爲它的親媽,是清華系AI 企業瑞萊智慧,背後的研究團隊,幾乎全是這裏面的人。
而在成立生數科技之前,團隊就已經把視頻大模型研究得很深入了。
尤其是在圖像生成這塊很火的擴散( Diffusion )模型,他們算是業內第一批研究這個模型的,整出來的論文也在 ICML 、 NeurIPS 、 ICLR 各種頂會發了個遍。
正是因爲有這麽好的底子,早在2022 年 9 月的時候,團隊就找到了做 Vidu 的靈感,就是下面這篇論文。

世超讓 AI 幫咱解讀了下,大概的思路就是,擴散模型在生成圖像這塊挺強,而大語言模型裏用的 Transformer 有個規模( Scale )效應,參數堆得越多,性能就越好。團隊就想著,能不能把這兩個的優點結合一下,整個融合架構,提升圖像生成的質量。
于是他們轉頭把擴散模型裏面的 U-Net 給換成 Transformer ,還起了個名字叫 U-ViT ( Vision Transformers )。結果試下來發現這麽一結合還真有用,光是相同大小的 U-ViT ,性能就比 U-Net 強了。
那好嘛,既然這條路走得通,他們也順勢把技術路線定在了 U-ViT 上。
然鵝。。。在團隊悄悄醞釀 Vidu 的時候,大洋彼岸的UC 伯克利的一個研究,卻讓 OpenAI 的 Sora 捷足先登了。
就在清華小分隊提交論文的兩個月後, UC 伯克利也在預印平台 ArXiv 上提交他們的論文了,一樣說要把 Transformers 揉在擴散模型裏面,只不過名字起的更直白了點,叫DiT( Diffusion Transformers )。
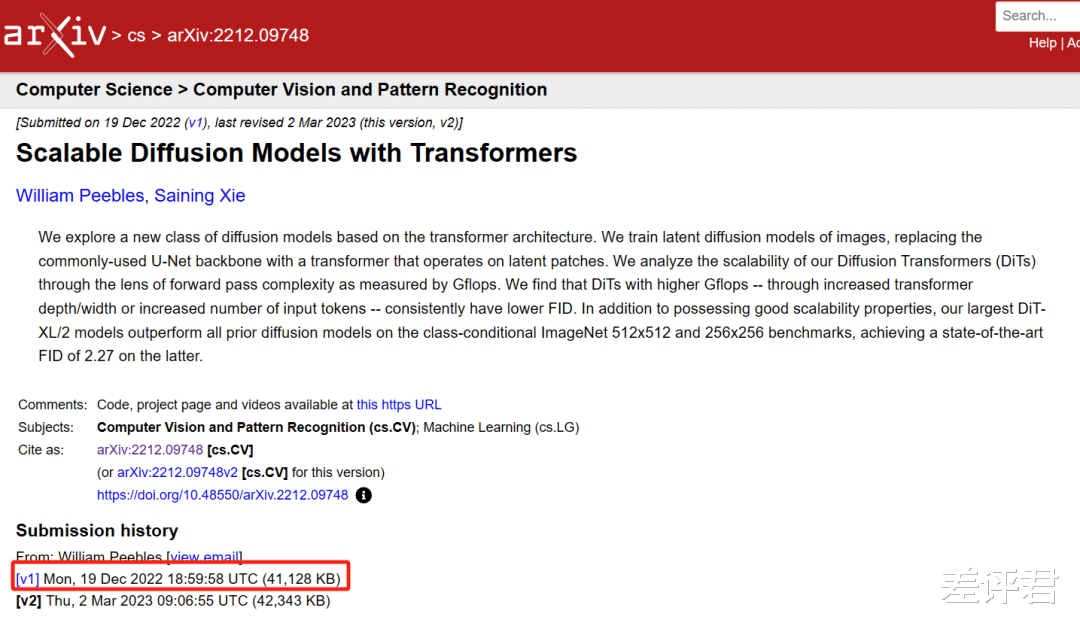
看著是不是挺眼熟,沒錯, OpenAI 的 Sora 模型,用的就是伯克利的 DiT 技術路線。
但因爲清華小分隊早發了兩個月,當年的計算機視覺頂會 CVPR 2023 還以“ 缺乏創新 ”的由頭,拒了 Sora 的 DiT ,收錄了 U-ViT 。
而且早在 2023 年年初的時候,清華小分隊還用 U-ViT ,訓練出了一個近 10 億參數量的開源大模型 UniDiffuser 。

算是第一個用行動證明了,融合架構也遵守 Scaling Law 這一套規則,也就是說隨著計算量、參數量越來越大,模型的性能就會隨指數級上升。而這個 Scaling Law ,同樣也是 Sora 這麽強的秘密武器。
所以照這麽來盤算,Sora 其實還得叫 Vidu 一聲祖師爺才對。。。
但現實世界卻是, DiT 被 OpenAI 帶著一路飛升。
清華小分隊呢,計算資源沒 OpenAI 那麽到位,也沒 ChatGPT 這種珠玉在前,總之就是啥啥都不完善,他們只能慢慢來,先做圖像、 3D 模型,等有家底兒了,再去做視頻。
好在他們身上還是有點實力在的,穩紮穩打慢慢也趕上來了。去年 3 月,清華小分隊們成立了生數科技後,就在馬不停蹄地搞自家的産品,現在圖像生成和 3D 模型生成大夥兒都能免費用了。
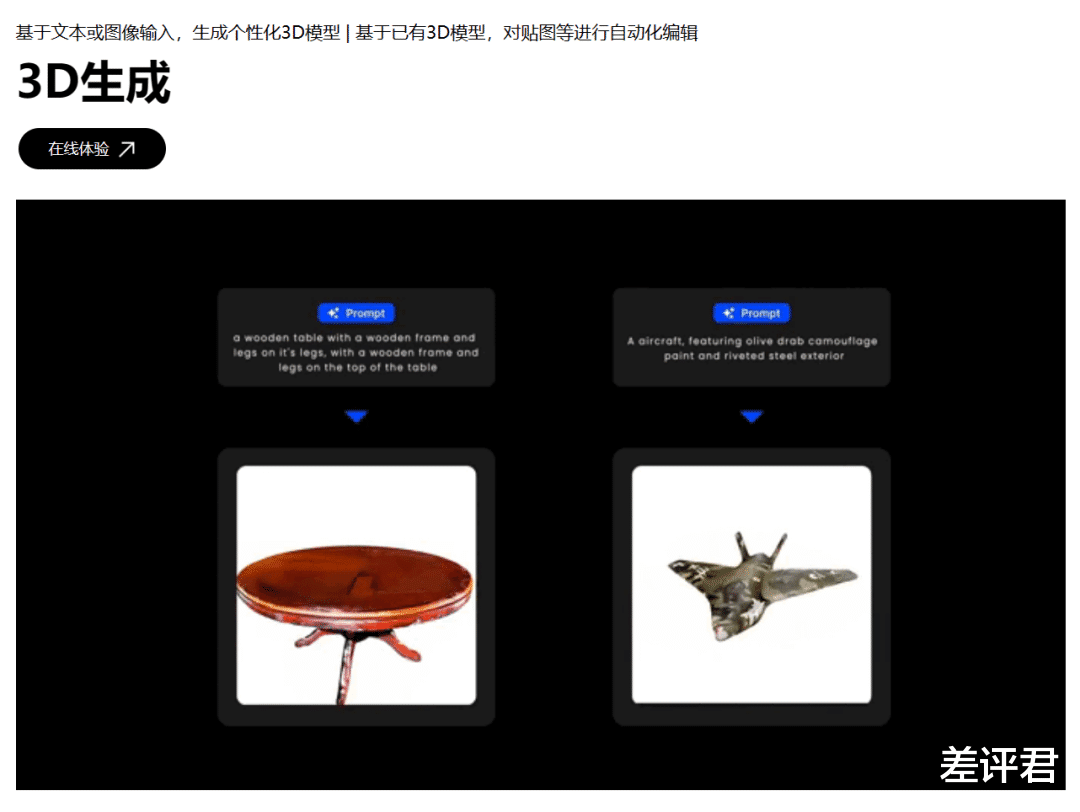
並且靠著這兩個産品,剛滿一周年,它就攢了好幾億的家底。
像是成立 3 個月的時候,就完成了一波近億級的天使輪投資,上個月,又完成了新一輪的數億元融資。參與投資的,也都是智譜 AI 、 BV 百度風投等等業內大佬。
反正看這波架勢, Vidu 還真有可能成爲國內的黑馬,去對標 OpenAI 的 Sora 。
不過生數科技那邊,倒是覺得只把 Vidu 看作國産版的 Sora ,實在是有點缺乏想象力了,因爲他們給 Vidu 的定位,可不僅僅是個視頻模型,而是圖、文、視頻全都要,只不過現在視頻暫時是重點。
當然了,好聽話誰都會說,能不能搞出來,咱還得實打實地看成品。
世超已經去排了隊,等拿到內測資格,再跟大夥兒同步一波。。。
