
01、術語與基礎
大模型訓練常采用8卡GPU集群,涵蓋A100、A800、H100、H800機型。以8*A100 GPU主機爲例,其內部硬件拓撲高效且強大,爲訓練提供強大算力支撐。

本節將基于這張圖來介紹一些概念和術語,有基礎的可直接跳過。
PCIe 交換芯片
支持PCIe的設備如CPU、內存、NVME存儲、GPU、網卡等,均可接入PCIe總線或專用交換芯片,實現高效互聯。目前PCIe已更新至第5代,即Gen5,展現了其技術的卓越發展。
NVLink定義
Wikipedia 上 NVLink 上的定義:
NVLink is a wire-based serial multi-lane near-range communications link developed by Nvidia. Unlike PCI Express, a device can consist of multiple NVLinks, and devices use mesh networking to communicate instead of a central hub. The protocol was first announced in March 2014 and uses a proprietary high-speed signaling interconnect (NVHS).
簡單總結:同主機內不同 GPU 之間的一種高速互聯方式:
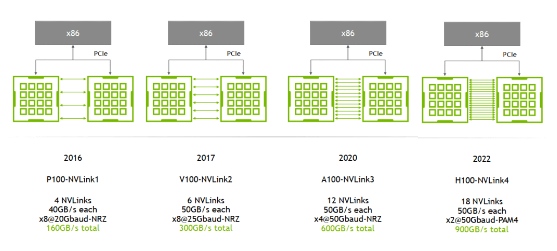
是一種短距離通信鏈路,保證包的成功傳輸,更高性能,替代 PCIe,支持多 lane,link 帶寬隨 lane 數量線性增長,NVLink實現同一node內GPU的full-mesh互聯,類似spine-leaf架構,確保高效數據傳輸與協同工作。NVIDIA 專利技術。演進曆程涵蓋1至4代,核心差異在于單條NVLink鏈路的lane數量及每lane的雙向帶寬。圖表直觀展示NVLink的進化,詳見HotChips 2022 [1]的研究成果。
A100擁有卓越性能,通過2條通道/NVSwitch乘以6個NVSwitch,每條通道高達50GB/s,實現驚人的600GB/s雙向帶寬(單向300GB/s),確保GPU與NVSwitch間的數據傳輸暢通無阻。A800精簡至8條lane,實現400GB/s雙向帶寬(單向高達200GB/s),每條lane傳輸速度達50GB/s,高效能傳輸,滿足您的數據需求。高效監控來襲!DCGM精准捕捉實時NVLink帶寬數據,確保性能無懈可擊。精准數據源自dcgm-exporter[5],爲您的監控策略提供有力支撐。
NVSwitch
NVSwitch 是 NVIDIA 的一款交換芯片,封裝在 GPU module 上,並不是主機外的獨立交換機。
下面是真機圖,浪潮的機器,圖中 8 個盒子就是 8 片 A100,右邊的 6 塊超厚散熱片下面就是 NVSwitch 芯片:

NVLink Switch
NVSwitch,並非普通交換機,而是GPU模塊上的交換芯片,專爲連接同主機GPU而設。2022年,NVIDIA創新推出NVLink Switch,真正實現了跨主機GPU設備的互聯。盡管名字相似,但功能與應用各有千秋,不容混淆。
HBM (High Bandwidth Memory)
由來
傳統上,GPU 顯存和普通內存(DDR)一樣插在主板上,通過 PCIe 連接到處理器(CPU、GPU), 因此速度瓶頸在 PCIe,Gen4 是 64GB/s,Gen5 是 128GB/s。
因此,一些 GPU 廠商(不是只有 NVIDIA 一家這麽做)將將多個 DDR 芯片堆疊之後與 GPU 封裝到一起 (後文講到 H100 時有圖),這樣每片 GPU 和它自己的顯存交互時,就不用再去 PCIe 交換芯片繞一圈,速度最高可以提升一個量級。這種“高帶寬內存”(High Bandwidth Memory)縮寫就是 HBM。
HBM 的市場目前被 SK 海力士和三星等韓國公司壟斷。
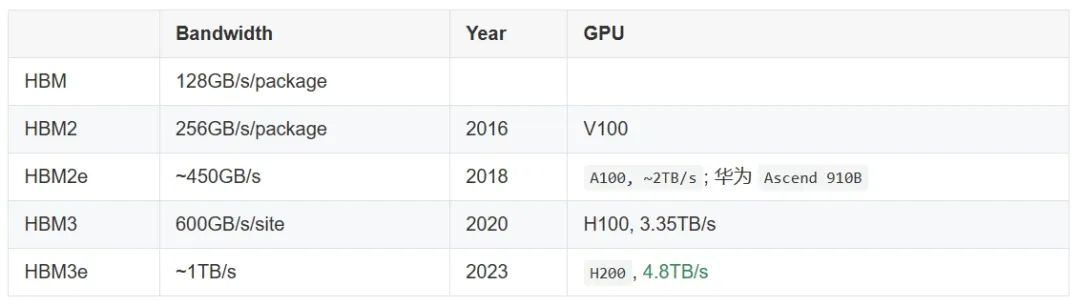
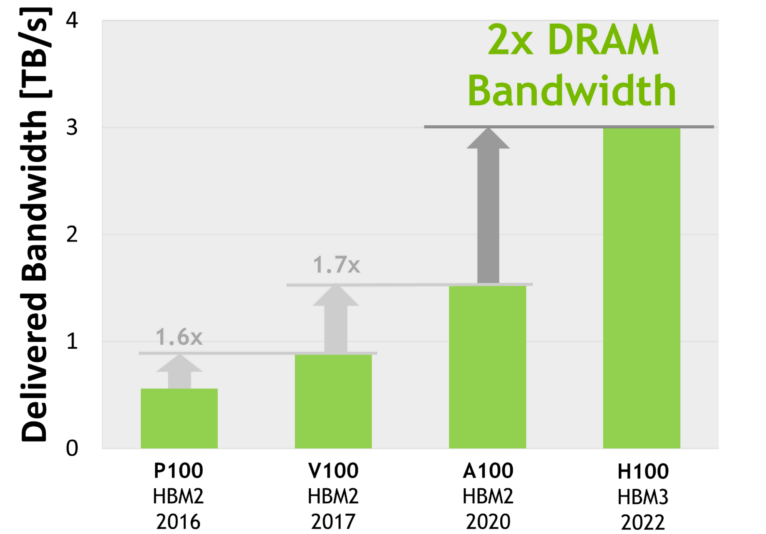
演進:HBM 1/2/2e/3/3e
帶寬單位
大規模GPU訓練性能受數據傳輸速度顯著影響,涵蓋PCIe、內存、NVLink、HBM及網絡等多鏈路帶寬,確保高效數據傳輸至關重要。
網絡習慣以bits/second (b/s)爲單位,且通常指的是單向傳輸(TX/RX)速度,衡量網絡性能的關鍵指標。其他模塊帶寬通常以B/s(字節/秒)或T/s(事務/秒)爲單位,反映雙向總數據傳輸或處理效率,確保高效通信與處理。比較帶寬時注意區分和轉換。
02、典型 8*A100/8*A800 主機
主機內拓撲:2-2-4-6-8-8
2 片 CPU(及兩邊的內存,NUMA)2 張存儲網卡(訪問分布式存儲,帶內管理等)4 個 PCIe Gen4 Switch 芯片6 個 NVSwitch 芯片8 個 GPU8 個 GPU 專屬網卡典型8卡A100主機硬件拓撲圖 呈現NVIDIA DGX A100的專業配置,官方認證的8卡機器硬件布局。特色在于存儲網卡直接通過PCIe與CPU相連,確保高效數據傳輸。專業之選,盡在NVIDIA DGX A100。
從分布式存儲讀寫數據,例如讀訓練數據、寫 checkpoint 等;正常的 node 管理,ssh,監控采集等等。強烈推薦BF3 DPU,但帶寬達標下選擇多樣。組網經濟型推薦RoCE,極致性能則首選IB。
NVSwitch fabric實現節點內全互聯,8個GPU通過6個NVSwitch芯片以full-mesh方式連接,形成強大的NVSwitch fabric。其每根線的帶寬高達n * bw-per-nvlink-lane,確保數據高效傳輸,爲您的業務提供卓越支持。
A100搭載NVLink3技術,實現高達50GB/s/lane的傳輸速度。在full-mesh結構中,每條線帶寬高達600GB/s(雙向),單向傳輸效率爲300GB/s,滿足高速數據傳輸需求。A800精簡版,12車道縮減至8車道,每條線仍達50GB/s,總計400GB/s,單向傳輸高達200GB/s,性能依舊卓越。利用`nvidia-smi topo`輕松洞察GPU拓撲。在配備8塊A800顯卡的服務器上,`nvidia-smi`揭示了詳盡的硬件連接結構,其中NIC 0~3已實現雙網卡綁定。專業數據,一屏掌握。
GPU 之間(左上角區域):都是 NV8,表示 8 條 NVLink 連接;NIC 之間:NODE適用于同CPU內跨PCIe交換芯片,無需跨NUMA;SYS則針對跨CPU操作,需跨越NUMA節點,確保高效數據處理與通信。
GPU 和 NIC 之間:CPU內部,若NODE位于同一PCIe Switch下,僅需跨交換芯片;若位于不同PCIe Switch但同CPU,則需跨交換芯片與Host Bridge;若跨越不同CPU,即SYS級,需跨NUMA與PCIe交換芯片,通信距離最遠。高效配置,確保數據傳輸迅速准確。
GPU 訓練集群組網:IDC GPU fabirc
GPU節點互聯架構揭秘:GPU網卡與置頂交換機直連,形成高效計算網絡。置頂交換機通過full-mesh技術連接至核心交換機(spine),構建跨主機GPU計算網絡,實現卓越性能與高效互聯。
這個網絡的目的是 GPU 與其他 node 的 GPU 交換數據;GPU與網卡間的高效互聯通過PCIe交換芯片實現,形成無縫橋梁:GPU直接連通PCIe Switch,再無縫對接NIC。存儲網絡:直連CPU的兩張網卡融入另一網絡,專注于數據讀寫與SSH管理。RoCE與InfiniBand兩大技術,皆爲RDMA之關鍵,支撐計算與存儲網絡,確保AI性能之高峰。在高性能追求中,這兩者皆不可或缺。
RoCEv2網絡是公有雲8卡GPU主機的主流選擇,如CX6的8*100Gbps配置,性能卓越且價格親民,爲您帶來高性價比的雲計算體驗。InfiniBand性能超越RoCEv2達20%以上,但價格高出一倍。追求極致性能,InfiniBand是首選。數據鏈路帶寬瓶頸分析
同主機GPU與網卡間,采用PICe Gen4 Switch芯片,實現高達64GB/s雙向傳輸,單向峰值達32GB/s,速度卓越。跨主機GPU通信需依賴網卡,受限于網卡帶寬。A100/A800機型標配帶寬達100Gbps(12.5GB/s單向),但跨機通信性能顯著低于主機內通信,需充分考慮網絡帶寬對性能的影響。200Gbps==25GB/s:已經接近 PCIe Gen4 的單向帶寬;400Gbps==50GB/s:已經超過 PCIe Gen4 的單向帶寬。對于此機型,400Gbps網卡效能受限,需PCIe Gen5支持方能盡顯其能。
典型配置爲8*H100/8*H800主機,GPU板卡形態分兩類,滿足多樣需求。
PCIe Gen5SXM5:性能更高一些H100 芯片 layout
4nm 工藝;最底部配備18根Gen4 NVLink,實現雙向總帶寬高達900GB/s,即18 lanes × 25GB/s/lane的卓越性能。中間藍色的是 L2 cache;左右兩側是 HBM 芯片,即顯存。主機內硬件拓撲
A100 8卡機結構升級,亮點凸顯:NVSwitch芯片精簡至4個,更高效;與CPU互聯技術升級至PCIe Gen5 x16,雙向帶寬高達128GB/s,大幅提升數據傳輸效率。真機圖展示,實力非凡,期待您的體驗!
組 網
與 A100 也類似,只是標配改成了 400Gbps 的 CX7 網卡, 否則網絡帶寬與 PCIe Switch 和 NVLink/NVSwitch 之間的差距更大了。
04、典型 4*L40S/8*L40S 主機
L40S 是今年(2023)即將上市的新一代“性價比款”多功能 GPU,對標 A100。除了不適合訓練基座大模型之外(後面會看到爲什麽),官方的宣傳裏它幾乎什麽都能幹。 價格的話,目前第三方服務器廠商給到的口頭報價都是 A100 的 8 折左右。
L40S vs A100 配置及特點對比
L40S獨具優勢,其time-to-market極短,遠超A100/A800/H800,這得益于技術和非技術因素的雙重優化,確保您快速獲取所需産品。
比如 FP64 和 NVLink 都幹掉了;使用 GDDR6 顯存,不依賴 HBM 産能(及先進封裝)。價格便宜也有幾方面原因,後面會詳細介紹:
整機成本顯著優化,如省去一層PCIe Gen4 Swtich。相較4x/8x GPU配置,其他部件成本幾乎可忽略,極具性價比。L40S 與 A100 性能對比
性能 1.2x ~ 2x(看具體場景);功耗:兩台 L40S 和單台 A100 差不多。務必注意,L40S主機官方推薦單機配置4卡而非8卡,原因後續揭曉。對比常采用兩台4*L40S與單台8*A100。性能提升的前提在于200Gbps RoCE或IB網絡的支持,下面將詳細解釋其重要性。
L40S 攢機
推薦架構優化:L40S GPU主機2-2-4架構
L40S GPU主機推薦采用精簡的2-2-4架構,相較A100的複雜布局,其物理拓撲更爲高效。此架構顯著特點在于移除CPU與GPU間的PCIe Switch芯片,實現網卡與GPU直接連接至CPU的PCIe Gen4 x16(64GB/s),大幅提升數據傳輸效率,爲高性能計算提供卓越支持。
2 片 CPU(NUMA)2 張雙口 CX7 網卡(每張網卡 2*200Gbps)4 片 L40S GPU另外,存儲網卡只配 1 張(雙口),直連在任意一片 CPU 上每片GPU享有高達200Gbps的網絡帶寬。然而,我們不建議采用2-2-8單機配置搭載8張L40S GPU的架構,這是基于NVIDIA L40S官方推介材料的考量。相較于單機4卡配置,8卡配置需額外引入兩片PCIe Gen5 Switch芯片,增加了複雜性和潛在風險。
PCIe switch 只有一家在生産,産能受限,周期很長;平攤到每片 GPU 的網絡帶寬減半。組網
官方建議 4 卡機型,搭配 200Gbps RoCE/IB 組網。
數據鏈路帶寬瓶頸分析
單機4卡L40S GPU主機帶寬瓶頸解析
在同CPU環境下,L40S提供兩種鏈路選擇:一是數據經CPU中轉,即GPU0通過PCIe與CPU連接,再由CPU經PCIe傳輸至GPU1。
此方案適用于數據處理需求不高、延遲要求不嚴格的場景。選對鏈路,高效利用帶寬,是提升GPU性能的關鍵。
PCIe Gen4 x16 雙向 64GB/s,單向 32GB/s;CPU 處理瓶頸?TODOGPU間通信革新:GPU0與GPU1間數據流轉,無需CPU幹預,直接經PCIe至網卡,再經RoCe/IB交換機返回,實現高效、低延遲的直通式數據傳輸。
PCIe Gen4 x16 雙向 64GB/s,單向 32GB/s;平均每個 GPU 一個單向 200Gbps 網口,單向折算 25GB/s;NCCL支持不可或缺,官方透露新版NCCL正專爲L40S適配,其默認行爲是執行外部環繞後回歸,更高效,更順暢。盡管第二種方式看似複雜,但官方證實其速度遠超方式一(CPU處理機制尚待深究)。關鍵在于網卡與交換機的配置:200Gbps RoCE/IB網絡,確保在帶寬充足的環境下,實現極速體驗。
GPU間通信的帶寬與延遲恒定,不受單機或CPU架構影響。這一特性使得集群能夠輕松實現橫向擴展(相對于縱向擴展),靈活滿足各種計算需求。GPU成本下降,但針對網絡帶寬需求不高的業務,NVLINK成本轉移至網絡。爲確保L40S多卡訓練性能發揮,組建200Gbps網絡成爲必要之選,確保最佳性能表現。L40S:200Gbps(網卡單向線速)A100:300GB/s(NVLINK3 單向) == 12x200GbpsA800:200GB/s(NVLINK3 單向) == 8x200GbpsL40S卡間帶寬相較于A100 NVLINK慢12倍,較A800 NVLink慢8倍,因此,在數據密集交互的基礎大模型訓練中,L40S並非理想選擇。
測試注意事項
如上,即便只測試單機 4 卡 L40S 機器,也需要搭配 200Gbps 交換機,否則卡間性能發揮不出來。
-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-
