編輯:Aeneas 好困
【新智元導讀】前谷歌量子計算團隊的幾位員工,如今創立了一家新公司,提出用物質隨機波動驅動計算。這種全新的計算方式,超越了傳統數字計算的約束,直接秒殺了當前的CPU和GPU。經典計算,一定是最好的方式嗎?
這家名叫Extropic的公司,選擇利用物質隨機波動驅動計算。

他們認爲,這種計算比經典計算機更快,更接近自然和我們大腦的計算方式。
因此,它擴展了硬件的性能界限,超越了傳統數字計算的約束。
比起當前的CPU、GPU、TPU、FPGA等數字處理器,這種全新的AI加速器快了數個數量級,而且更加節能。
因爲,這種新方法使得在數字處理器上不可行的強大概率AI算法,成爲可能。

創始人40分鍾視頻上線,網友吐槽沒講清楚
最近,公司創始人Gill Verdon的一段長達40分鍾的采訪視頻上線了。

視頻地址:https://www.youtube.com/watch?v=QjVOfM2EBnE
整個訪談的畫面,就是聯合創始人Guillaume Verdon和主持人Jason Carman的一問一答。


在留言區,反響十分熱烈。
一些網友表示內容非常優質,簡直好到爆。

「多麽吸引人的紀錄片啊!爲什麽社交媒體上沒人討論,太奇怪了。」

但仔細聽完這段訪談的一位網友,給出了這樣的反饋:整整40分鍾,都沒有解釋清楚芯片的工作原理和架構……
他猜測,原因可能是創始人沒有想好是將技術保密,還是選擇向公衆公開。
或者,就是他覺得觀衆太笨無法理解,或者純粹是表達能力太差。
看到網友的質疑,公司成員Beff Jezos趕緊發了條超長的QA,重新解釋了一遍:
問:模擬神經網絡並不是新事物,IBM/Intel等公司嘗試過類腦計算,爲什麽它們都沒成功?
答:確實,類腦計算已經被研究很長時間了。這些系統通常需要使用特殊的組件,如憶阻器(memristors)等,或者過度追求模仿生物特性,如脈沖神經網絡(spiking neural networks)。
但是,這些系統往往無法直接與最終應用對接,也很難找到有效的訓練方法。而Extropic就在解決這些問題,還會通過論文分享自己的研究成果。
問:關于模擬計算的一般情況是怎樣的?
答:以往的模擬計算,主要集中在確定性算法上。
在這方面想取得突破非常難,因爲確定性的微分方程可以通過固定的開銷進行離散化,並在數字計算機上解決,這就極大限制了模擬計算的加速潛力。
隨機動力學則與之不同。模擬隨機系統的數字算法通常收斂性較弱,且每個時間步驟所需的計算量遠超其確定性的對應算法。
因此,盡管存在一些困難,采用隨機模擬方法是有其合理性的。
問:爲什麽現在才開始使用隨機模擬技術?
答:直到最近,我們才具備了構建真正隨機模擬計算機的技術條件。
即便在室溫環境下,熱波動也非常微小,只有非常微小的物理系統才會受到顯著影響。而在電路設計上,這種微小化要求意味著需要具備幾百阿托法拉(aF)的特征電容,這種電容只能通過較新的CMOS工藝來實現。
因此,以前從未有過真正的基于熱動力學的電路計算機被造出來。也是因此,隨機模擬技術從未得到充分的試驗。
圖源:https://www.youtube.com/watch?app=desktop&v=oSrUsM0hoPs
問:爲什麽選擇超導技術?爲什麽選擇CMOS技術?
答:僅包含線性元件(如電阻、電容和電感)的隨機電路,只能從高斯分布中進行抽樣,這在實際應用中顯然是有限的,尤其是電感的體積通常較大,但是,數字計算機在這方面已經已經卓有成效了。
我們選擇超導技術作爲起點,是因爲通過約瑟夫森結,就可以實現非線性哈密頓動力學的模擬,這不僅跟我們的研究起點相一致,也是因爲隨機哈密頓系統在理論上非常優雅。
然而,超導系統需要在幾開爾文的低溫下工作,這限制了它的實用性,而且大幅增加了工程複雜性。
因此,我們需要自然而然地探索,如何在大規模可制造的環境中構建非線性隨機系統。顯然,選擇CMOS是自然而然的。
當前的挑戰,就是清楚理解隨機狀態下晶體管的工作原理。對此,我們已經取得了重大進展,並且期待盡快構建出實用、可擴展的系統。

問:模擬技術中,處理相關噪聲源特別困難,你們有什麽應對策略嗎?
答:確實,這是一個複雜的問題。我曾經參與Google Quantum的一個項目,團隊需要對設備進行精密校准,以模擬並糾正複雜的相關噪聲,這是實現首次量子霸權實驗的關鍵。
Trevor曾在該團隊工作數年,專注于噪聲物理和硬件問題,他在MIT的博士研究也是圍繞這個主題,並發表了多篇論文。

問:硬件的個體差異很大,每個芯片都有其獨特性,你們怎麽處理這種情況?
答:盡管硬件的個體差異帶來了挑戰,但你日常使用的設備,從汽車到智能手機,大多數都能正常工作。這並非偶然,而是因爲背後有很多工程師,花費了大量時間,開發了複雜的特性化、校准和補償技術,有效減少了這些差異對用戶的影響。
在Extropic,我們也采用了類似的方法。幾十年來,我們在隨機CMOS芯片領域積累了豐富經驗,加快了研發進程。此外,我們計劃針對每個芯片的獨特物理特性,進行個性化的訓練和微調,包括它們的瑕疵。
我們不僅進行推理計算,還計劃在芯片上直接進行訓練。像訓練大腦一樣,這種帶著缺陷進行的訓練,能使芯片更好地適應這些個性化的差異。
問:設計、驗證、測試非常複雜,當前的工具是否支持你們設備運行的模式(例如,海森堡極限)?
答:我們的CMOS設備並不是在量子模式下運行,而是在隨機模式下。的確這個流程非常複雜,但我們內部有一些超低功耗晶體管的先進模型,是由我們的硬件物理專家團隊開發的。
我們不僅有豐富的經驗,還有頂尖的人才。在測試和表征噪聲方面,這是許多團隊成員在量子計算領域多年職業生涯中的專長。

圖源:https://www.youtube.com/watch?app=desktop&v=6Qc4BvToD3Y
問:數字硅技術已經非常成熟,爲什麽還要與整個技術棧競爭?你們如何從實驗室規模擴展到大規模制造?
答:我完全同意這一點。相較于超導技術,CMOS的供應鏈和工具更爲成熟,這也是我們使用CMOS並盡可能利用現有工具和供應鏈的原因。我們的目標是,將Extropic芯片最終應用于大多數需要神經計算功能的設備中。
問:你們有進行任何模擬研究嗎?計劃提供模擬器嗎?
答:是的,我們從一開始就在使用隨機模擬進行設計。目前,我們正在准備詳盡的科學論文,計劃開源部分代碼。
不過最主要的挑戰是,由于需要模擬時間加速,這些模擬需要大量的計算資源,因此在普通的筆記本電腦或台式機上運行這些模擬並不現實。
問:超導技術和低溫技術難以大規模應用,難以觸及大衆市場,你們有什麽應對策略?
答:在此領域工作多年,我們深知超導技術難以規模化。對我們而言,這主要是一個測試平台,用于驗證我們關于電子的參數隨機物理學的理念,以及我們的編程模型。
這是我們能制造的最接近宏觀的真實熱力學芯片,它利用環境熱量的自然噪聲,但必須經過極度冷卻,才能達到理想工作狀態。而下一代芯片,就將采用CMOS技術,來大幅減少對低溫技術的依賴,做到能在室溫下正常工作。

問:爲什麽重視采樣擴散過程?
答:如果你使用過擴散模型,就會注意到DALLE或Midjourney生成圖像的速度有多慢。視頻擴散的緩慢程度也差不多。這些實例都證明,神經擴散過程需要大幅提速。
通過直接利用模擬隨機電子物理學,我們就能顯著提高處理速度。具體的性能基准將在即將發布的白皮書中詳細介紹,敬請關注!
開創熱力學的未來
在3月份,公司也發表了博客,解釋這個了這個「熱力學計算機」的原理。
Extropic表示,自己正在開發的這個項目是一個全棧硬件平台,可以將物質自然的波動作爲計算資源,從而爲生成式AI提供支持:
突破傳統數字計算的限制,將硬件的擴展能力推向新的高度。使AI加速器的速度和能效遠遠超過傳統的數字處理器(CPU/GPU/TPU/FPGA),提升可達好幾個數量級。可以完成那些在傳統數字處理器上無法實現的強大概率性AI算法。
能量基模型(EBMs)這一概念在熱力學物理和基礎概率機器學習中均有出現。
在物理學中,它們被稱爲參數化熱態,由具有可調參數的系統的穩態産生。在機器學習領域,則被稱爲指數族。
指數族是參數化概率分布的理想方式,它們能夠用最少的數據量准確確定參數。
在數據較少的情況下,指數族尤爲有效,適用于需要在關鍵任務應用中對尾部事件進行建模的場景,如圖1所示。
它們通過在數據空白處引入噪聲來實現這一目標,努力在保持目標分布統計特性的同時,最大化熵值。

圖1:Extropic概率性AI加速器的基本原理
能量基模型(EBMs)在生産應用中面臨的主要挑戰是采樣需求。
在數字硬件上,從通用能量景觀中進行采樣非常困難,因爲這需要硬件消耗大量電能來産生和調整擴散過程所需的熵。
Extropic通過將能量基模型直接實現爲參數化的隨機模擬電路,有效地解決了這一低效問題。與數字計算機相比,Extropic加速器在運行時間和能源效率方面將實現多個數量級的改進。
具體來說,Extropic加速器的工作原理與布朗運動相似。
在布朗運動中,宏觀但輕質的粒子在流體中懸浮,由于與微觀液體分子的頻繁碰撞,這些粒子會經曆隨機的力,導致它們在容器中隨機移動。
如圖2(a)所示,可以想象,通過彈簧將布朗粒子固定在容器壁和彼此之間。這樣,彈簧會抵抗隨機力,使得粒子傾向于聚集在容器的某些特定區域。
如圖2(b)所示,如果不斷地重複采樣粒子的位置,並在兩次樣本之間留出足夠的時間我們會發現它們遵循一個可預測的穩定的概率分布。
通過改變彈簧的剛度,我們可以調整這個分布。這種簡單的機械系統提供了一種可編程的隨機性。

圖2:Extropic加速器的運行原理
(a)Extropic加速器的簡單機械類比。因爲設備涉及三個質量點在兩個維度上的活動,其穩定狀態將對應一個六維空間的概率分布;
(b)從Extropic加速器中抽取樣本的方法是,反複觀察系統,並確保每次觀察之間至少有一個平衡時間teq。這個平衡時間teq是指系統中的噪聲消除與前一個樣本相關性所需的時長。
這個機械模型直接關聯到構成Extropic加速器的參數化隨機模擬電路。
這裏,輕質粒子相當于電子,而液體分子則是導電介質中的原子,它們在碰撞中能將能量傳遞給電子。彈簧則代表了限制電子運動的電路元件,比如電感或晶體管。通過施加控制電壓或電流,可以調整這些元件的參數,進而改變電路的采樣分布。
雖然每個電路都存在噪聲,但並非所有電路都適合用作Extropic加速器。
從工程學的角度來看,打造一個以噪聲爲主導且表現穩定的設備頗具挑戰性。由于熱波動較小,這類設備必須設計得足夠小且功率低,以便顯著受到這些波動的影響。
因此,如果想利用宏觀組件(如在印刷電路板上)來構建Extropic加速器,就必須引入人造噪聲。但這種做法會削弱設備在時間和能源節省方面的基本優勢,最終的性能可能與數字執行算法相似。
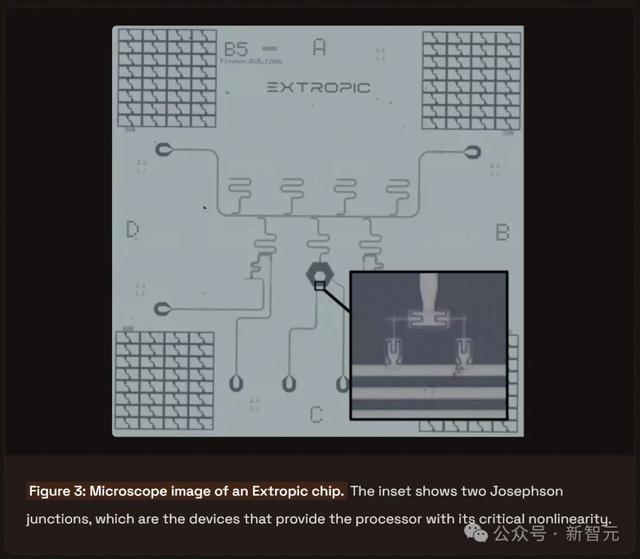
圖 3:Extropic芯片的顯微鏡圖像。圖中小圖展示了兩個Josephson結,這些是爲處理器提供關鍵非線性功能的設備。
這些神經元構成了基本單元,組合起來可以構建一個更大的超導系統。
在這種大型系統中,多個線性和非線性神經元結合,形成一個能從豐富且高維的分布中采樣的電路。神經元的偏置和相互作用強度都是可調整的參數,使得單一設備能夠支持多種概率分布。
Extropic的超導芯片完全是被動式的,這意味著只會在測量或調整其狀態時才消耗能量。這可能使得這些神經元成爲全宇宙中最節能的。
Extropic還在開發可在常溫下運行的半導體設備,以便擴大市場。
這些設備用晶體管替代了Josephson結,雖犧牲了一些能效,但可利用標准的制造流程和供應鏈進行生産,從而大規模生産。
由于這些設備可以在常溫下運行,因此可以將它們設計成類似GPU的擴展卡形式。這將使我們能夠在每個家庭中安裝一個Extropic加速器,讓每個人都能體驗到熱力學AI加速的優勢。
爲了支持多種硬件平台,Extropic正在開發一個軟件層,從而將能量基函數模型的抽象規範轉換爲相應的硬件控制語言。
這個編譯層基于因子圖(factor graphs)的理論框架,因子圖描述了大型分布如何分解爲局部塊。這使得Extropic加速器能夠拆解並運行那些單個模擬核心無法完全承載的龐大程序。
許多以前的AI加速器公司因爲深度學習的內存限制而難以獲得優勢——現今的算法約有25%的時間用于在內存中移動數據。
因此,根據Amdahl定律,任何專門加速某一操作(如矩陣乘法)的芯片都難以實現超過4倍的速度提升。
Extropic芯片能夠本質上通過物理方式快速且高效地運行廣泛的概率算法,從而有望開啓一個全新的人工智能加速時代,遠超過之前認爲可能的水平。
參考資料:
https://www.extropic.ai/future
https://twitter.com/jasonjoyride/status/1784638854798123241
https://twitter.com/BasedBeffJezos/status/1784760185371967916
