
攝像頭的邊界在哪裏?毫末智行聯合相關機構提出的專爲僅使用攝像頭進行4D占用預測而設計的基准測試,有望進一步放大攝像頭在自動駕駛領域的感知邊界。
文丨智駕網 王欣
爲了確保自動駕駛汽車在行駛中能夠安全、可靠地執行任務,了解周圍環境的變化至關重要。近年來,一些技術能夠通過分析攝像機圖像來估計周圍物體的位置和分布,這對于理解大規模場景的結構非常有幫助。
然而,這些技術主要關注的是當前的3D空間,對于未來物體可能的位置和狀態並沒有太多考慮。
爲了解決這個問題,最近,毫末智行聯合上海交大、國防科大、北京理工大學提出了一種新的方法,叫做Cam4DOcc。
這是一個專門爲僅使用攝像頭進行4D占用預測而設計的基准測試,用于評估未來一段時間內周圍場景的變化。
Cam4DOcc基准測試的目標是使用攝像頭圖像作爲輸入,預測當前和未來短時間內(通常是幾秒內)的3D空間占用狀態。
包括對一般可移動物體(GMO)和一般靜態物體(GSO)的占用狀態進行預測。預測任務又分爲多個級別,從預測膨脹的GMO到預測精細的GMO、GSO和自由空間。
Cam4DOcc基准測試爲自動駕駛中的4D占用預測提供了一個標准化的評估平台,使研究人員能夠比較不同算法的性能。通過這些測試,研究人員可以更好地理解和改進自動駕駛系統在理解和預測周圍環境方面的能力。
毫末預測,自動駕駛領域中下一個重要的挑戰將是僅使用攝像頭進行4D占據預測。這項技術不僅可以通過攝像頭圖像擴展時間上的占據預測,還要在BEV格式和預定義類別之外拓展語義/實例預測。
該論文的主要核心貢獻包括:
提出了Cam4DOcc基准,這是第一個促進基于攝像頭的4D占用預測未來工作的基准。
通過利用現有數據集,提出了自動駕駛場景中預測任務的新數據集格式。
提供了四種新穎的基于攝像頭的4D占用預測基線方法,其中三種是現成方法的擴展。
還引入了一個新穎的端到端4D占用預測網絡,展示了強大的性能,爲研究者提供了有價值的參考。
論文引入了標准化評估協議,並通過Cam4DOcc基于該協議進行了全面的實驗和詳細的分析。
下面我們來詳細剖析這篇論文。
01.
解鎖自動駕駛時空預測的超能力
該論文首先提出了一個新的數據集格式。
該格式基于現有的數據集(包括nuScenes、nuScenes-Occupancy和Lyft-Level5)進行了擴展和調整,這樣就可以適應4D占用預測的需求,這裏需求就包括關于可移動和靜態物體的連續占用狀態,以及它們的3D向後向心流的信息。
下圖爲以原始和Scenes-Occupancy爲基礎,在Cam4DOcc中構建數據集的整體流程。
通過利用現有數據集,提出了自動駕駛場景中預測任務的新數據集格式被重組爲一種新穎的格式,既考慮了一般的活動類別,也考慮了靜態類別,用于統一的四維空間占用預測任務。
如下圖所示,論文首先將原始nuScenesnu分割成時間長度爲N = Np+Nf+1的序列。然後按順序對可移數據集動物體進行語義和實例注釋,並收集到 GMO 中。
包括自行車、公共汽車、汽車、建築、摩托車、拖車、卡車和行人,它們都被轉換爲當前坐標系(t = 0)。
之後,再對當前3D空間進行體素化,並使用邊界框注釋語義/實際標簽附加到可移動對象的網格。
值得注意的是,在此過程中,一旦出現以下情況,無效實例就會被丟棄。
(1)如果它是 Np 個曆史幀中新出現的對象,則其可見性在 6 個攝像機圖像中低于 40%
(2)它首先出現在 Nf 個傳入幀中或者
(3)它超出了在 t = 0 時預定義的範圍(H,W,L)。可見性通過相機圖像中顯示的實例的所有像素的可見比例來量化[29]。基于恒定速度假設[22]、[44],利用順序注釋來填充缺失的中間實例。相同的操作也適用于 Lyft-Level5 數據集。
最後,論文作者利用Lyft-Level5數據集生成3D中的實例關聯生成三維向心流。利用此3D流來提高基于攝像頭的4D 占用預測的准確性。
該論文的目標不僅是預測GMO的未來位置,還要估計GSO的占用狀態和安全導航所需的自由空間。因此,作者們又進一步將原始nuScenes中的順序實例注釋與從nuScenes-Occupancy轉換到當前幀的順序占用注釋連接起來。這種組合平衡了自動駕駛應用中下遊導航的安全性和精度。GMO標簽借鑒了原始nuScenes的邊界框標注,可以看作是對可移動障礙物進行了膨脹操作。GSO 和免費標簽由nuScenes-Occupancy提供,專注于周圍大型環境的更細粒度的幾何結構。
介紹完數據集,接下來是評估協議。爲了充分發揮僅使用攝像頭的 4D 占用預測性能,作者在 Cam4DOcc 中建立了具有不同複雜程度的各種評估任務和指標。
論文在標准化評估協議中引入了四級占用預測任務:
(1)預測膨脹的GMO:所有占用網格的類別分爲GMO和其他,其中來自nuScenes和LyftLevel5的實例邊界框內的體素網格被注釋作爲GMO。
(2)預測細粒度GMO:類別也分爲GMO和其他,但GMO的注釋直接來自nuScenes-Occupancy的體素標簽,去除了第2節中介紹的無效網格。
(3)預測膨脹的GMO、細粒度GSO和自由空間:類別分爲來自邊界框注釋的GMO、遵循細粒度注釋的GSO和自由空間。
(4)預測細粒度GMO、細粒度GSO和自由空間:類別分爲GMO和GSO,均遵循細粒度注釋,和自由空間。由于 Lyft-Level5 數據集缺少占用標簽,因此作者僅對其第一個任務進行指標評估。對于所有四個任務,作者使用交並集(IoU)作爲性能指標。作者分別評估當前時刻 (t = 0) 占用率估計和未來時間 (t ∈ [1, Nf ]) 預測:
其中St'和St分別表示時間戳t處的估計體素狀態和真實體素狀態,更接近當前時刻的時間戳的IoU對最終的IoUf貢獻更大。這符合“接近時間戳的占用預測對于後續運動規劃和決策更爲重要”的yuan。
接下來,論文作者們又提出了四種基線。
爲了建立一個全面比較的基准,基于攝像頭的感知和預測功能,論文引入了四種不同類型的基線方法。
這些方法包括靜態世界占用模型、點雲預測的體素化、基于2D-3D實例的預測。這些基線方法爲論文提供了一個框架,以便可以比較和評估各種方法在當前和未來占用估計方面的性能。
靜態世界占用模型可以理解爲一種假設環境在短時間內保持不變的簡單方法。在這種假設下,當前估計的占用網格可以作爲所有未來時間步的預測。這種方法僅基于靜態世界假設,即在預測的時間範圍內,場景中的物體不會發生顯著的運動變化。(如下圖)
點雲預測的體素化是指將點雲預測的結果轉換爲體素(voxel)表示的一種方法。
一般這個過程涉及幾個步驟:
深度估計:首先,使用環視攝像頭捕獲的圖像,通過深度估計算法生成連續的周圍視圖深度圖。
點雲生成:接著,通過射線投射(ray casting)技術,將深度圖轉換爲3D點雲。這個過程模擬了激光雷達(LiDAR)的工作原理,通過多個攝像頭的深度信息來重建三維空間中的點。
點雲預測:使用現有的點雲預測方法(如PCPNet)來預測未來時間步的3D點雲。這些方法通常基于當前的點雲數據,通過學習點雲隨時間變化的模式來預測未來的點雲。
語義分割:預測得到的點雲通過語義分割算法(如Cylinder3D)進行處理,以提取可移動和靜態物體的點級標簽。
體素化:最後,將預測得到的點雲轉換爲體素表示,即將每個點映射到一個三維網格中,形成占用網格(occupancy grid)。這樣,每個體素代表一個空間體積,其值表示該空間是否被物體占據。
這種方法的關鍵作用在于,它能夠將點雲預測的結果轉換爲一種適合于占用預測的格式,即體素化表示。通過這種方式,可以更好地評估和比較不同預測方法在自動駕駛場景中對動態和靜態物體未來狀態的預測能力。
基于2D-3D實例的預測指的是一種基于實例的預測方法,它使用環繞視圖攝像頭來預測近未來的語義場景,包括車輛、行人等動態物體的位置和運動。這種方法是作爲Cam4DOcc基准中的一個基線提出的,用于評估和比較不同的4D占用預測方法。
當然,在智駕網看來,基于2D-3D實例的預測方法也有一定局限性。
這個方法涉及到2D實例預測的步驟,2D實例預測是指使用2D鳥瞰圖(BEV)格式的實例預測算法(如PowerBEV)來預測動態物體在未來時間步的語義分布。這些算法直接從多視圖2D攝像頭圖像中提取BEV特征,並結合時間信息來估計未來的實例分布。
局限就在于它依賴于2D BEV格式的預測,並且假設所有動態物體在同一高度上運動,這可能不適用于所有場景,特別是在複雜的城市環境中。
上述三種基線在執行任務過程中都存在局限性,因爲不能直接預測未來三維空間的占用狀態,它們需要額外的後處理——根據現有結果擴展和轉化爲四維空間占用預測。
因此,論文也提出了端到端的4D占用預測網絡OCFNet。
02.
OCFNet:端到端4D占用預測的創新
OCFNet能夠直接從攝像頭圖像中預測3D空間的未來占用狀態,而不需要依賴于2D到3D的轉換。
OCFNet通過接收連續的環繞視圖攝像頭圖像,能夠同時預測當前占用狀態和未來占用變化。該網絡利用多幀特征聚合模塊和未來狀態預測模塊,不僅預測了物體的占用狀態,還預測了物體的運動流,爲自動駕駛車輛提供了更爲豐富和精確的信息。
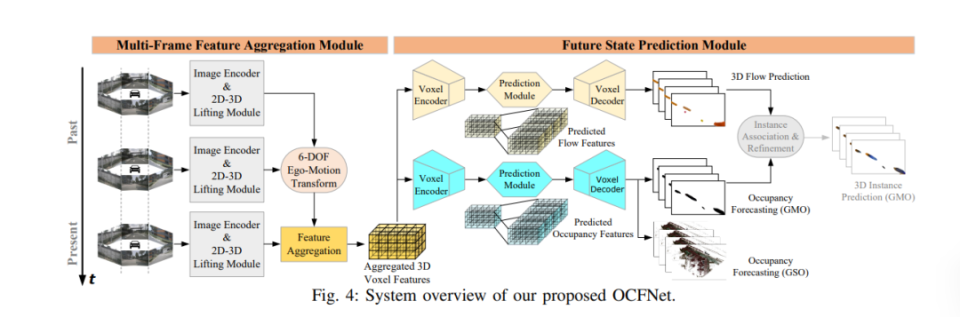
最後論文結果分析,OCFNet的性能在多個任務上超過了第一段分析的三個基線方法(靜態世界占用模型、點雲預測的體素化、2D-3D實例基礎預測)。
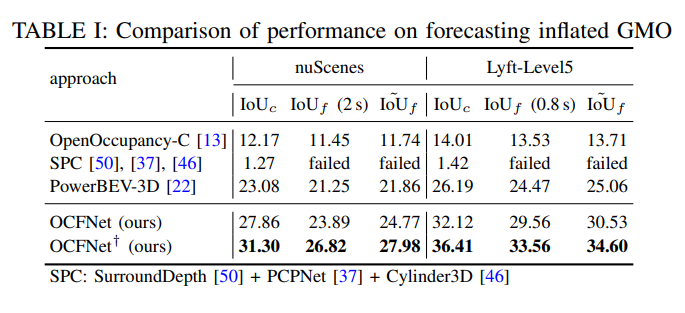
比如下圖中的實驗任務是預測nuScenes和LyftLevel5上的GMO。這裏OpenOccupancy-C、PowerBEV和OCFNet僅使用膨脹的GMO標簽進行訓練,而PCPNet則通過整體點雲進行訓練。OCFNet和OCFNet†優于所有其他基線,在 nuScenes上的IoUf和IoUf'上超過基于BEV的方法12.4%和13.3%。在Lyft-Level5上,作者的OCFNet和OCFNet†在 IoUf和IoUf'方面始終優于PowerBEV-3D 20.8%和21.8%。
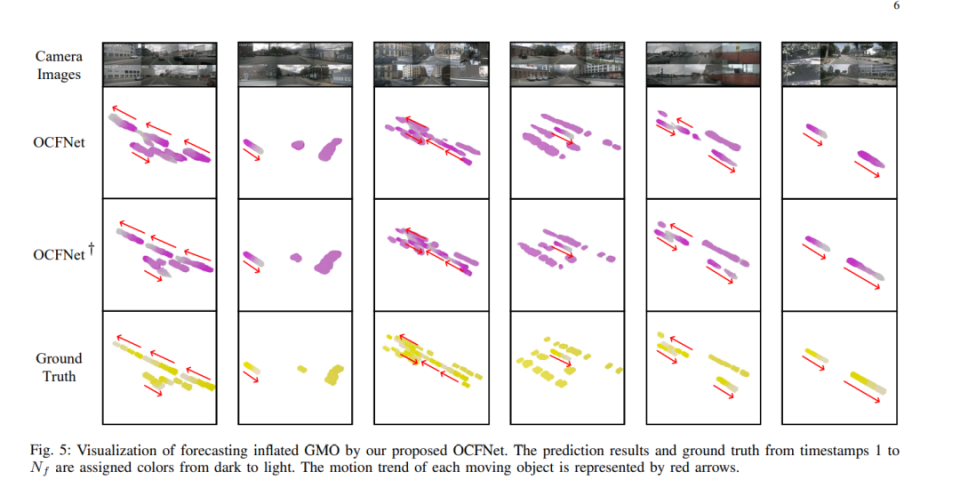
下圖顯示了OCFNet和CFNet†對nuScenes GMO占用率進行預測的結果,這表明僅使用有限數據訓練的OCFNet仍然可以合理地捕獲GMO占用網格的運動。此外,預測對象的形狀在未來的時間步長中會顯著失去一致性。OpenOccupancy-C的性能遠優于點雲預測基線,但與PowerEBV-3D和OCFNet相比,估計當前占用率和預測未來占用率的能力仍然較弱。
通過在提出的Cam4DOcc基准上運行所有基線方法,作者收集了詳細的性能數據。評估指標包括交並比IoU和視頻全景質量(VPQ),這些指標衡量了模型在當前和未來時間步的占用預測准確性。
結果表明,OCFNet在多個任務上都取得了更高的IoU分數,這表明在預測當前和未來的占用狀態方面更爲准確。
爲了進一步證明OCFNet的優勢,作者還進行了消融研究,展示了網絡中不同組件(如流預測頭)對性能的貢獻。
下圖實驗表明,在當前和未來的占用率估計中,完整的OCFNet比沒有流預測頭的OCFNet增強了約 4%。原因可能是 3D 流程指導學習每個時間間隔的 GMO 運動,從而幫助模型確定下一個時間戳中占用估計的變化。

簡單來講,OCFNet的優勢在于,通過端到端的方式直接預測未來的占用狀態,減少了傳統方法中的僞影,提供了更准確的預測結果。
盡管OCFNet取得了顯著的成果,但如若應用在未來的工作上,對于更長時間段內多個移動物體的預測,論文認爲這一任務仍然具有挑戰性。不過未來的工作可以在此基礎上進一步提高預測的准確性和魯棒性。
03.
說到最後,端到端的技術興起背後
馬斯克的第一性原理同樣可以化套用在自動駕駛的能力上。
如果從第一性原理來講,自動駕駛就是一個序列到序列的映射過程,輸入的是一個傳感器信號序列,可能包括多個攝像頭采集到的視頻、Lidar采集到的點雲、GPS、IMU 等各類信息,輸出的是一個駕駛決策序列,例如可以是駕駛動作序列,也可以輸出軌迹序列再轉爲操作動作。
這個過程與大部分AI任務基本一致,這種映射過程就相當于一個函數y= f(x),但實現這種函數難度較大,任務複雜,一般解決方式包括分治法、端到端、傳統分治法等。
端到端的方式原理最爲簡單——直接尋找一個函數實現y=f(x)。
相比之下,端到端自動駕駛不進行任務切分,希望直接輸入傳感器數據、輸出駕駛決策(動作或者軌迹),從而抛棄傳統自動駕駛裏的感知、預測、規劃、控制等各類子任務。這種方式有明顯的優勢,例如:
•效果上:不但系統更簡單,還能實現全局最優。
•效率上:由于任務更少,避免了大量重複處理,可以提高計算效率。
•數據收益:不需要大量的人工策略、只需要采集足夠多的優質駕駛數據來訓練即可,可以通過規模化的方式(不斷擴展數據)來不斷提升系統的能力上限。
一個典型的端到端自動駕駛系統如圖所示:
輸入:大部分自動駕駛汽車都裝載了攝像頭、Lidar、毫米波雷達等各類傳感器,采集這些傳感器的數據,輸入深度學習系統即可。
輸出:可以直接輸出轉向角、油門、刹車等控制信號,也可以先輸出軌迹再結合不同的車輛動力學模型,將軌迹轉爲轉向角、油門、刹車等控制信號。
可見,端到端自動駕駛系統就像人類的大腦,通過眼睛、耳朵等傳感器接收信息,經過大腦處理後,下達指令給手腳執行命令……但是這種簡單也隱藏了巨大的風險,例如可解釋性很差,無法像傳統自動駕駛任務一樣將中間結果拿出來進行分析;對數據的要求非常高,需要高質量的、分布多樣的、海量的訓練數據,否則 AI 就會實現垃圾進垃圾出。

與傳統的自動駕駛方式對比可見,同樣的輸入、同樣的輸出,傳統自動駕駛包含多個任務(多個模塊),但是端到端只有一個任務。此處容易産生一個誤區,即認爲傳統的自動駕駛是多模塊的、端到端自動駕駛是單模塊的,把分模塊與分任務的概念搞混了。
傳統的自動駕駛是分任務的,必然是多個模塊。端到端自動駕駛可以用單模塊來實現,當然也可以用多模塊來實現,其區別在于是否端到端訓練。分任務系統是每個任務獨立訓練、獨立優化、獨立測評的,而端到端系統是把所有模塊看成一個整體進行端到端訓練、端到端測評的。
例如2023年CVPR best paper提出的UniAD就是一種分模塊端到端訓練方式,這種方式通過端到端訓練避免了多任務訓練的融合難題實現全局最優,又保留了分模塊系統的優勢、可以抛出中間模塊的結果進行白盒化分析,反而更具靈活性對部署也更友好,如圖所示:
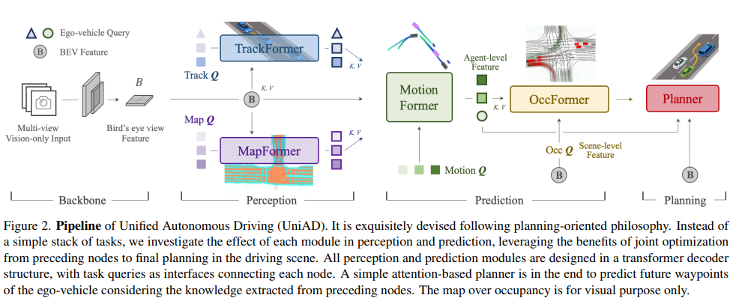
分任務的自動駕駛系統更像model centric系統,開發者通過不斷優化各個模型來提升各個任務的效果。而端到端自動駕駛則更像data centric系統,通過對數據的調優來提升系統效果。
早年,由于自動駕駛積累的數據還非常少,端到端系統的效果往往比較差。最近幾年,隨著帶高階輔助駕駛功能的量産車大規模落地,通過海量量産車可以采集到豐富的駕駛數據,覆蓋各類場景,再加上最近幾年 AI 算力的蓬勃發展,端到端自動駕駛在海量數據、海量算力的加持下,取得了突破性進展。
以特斯拉爲例,通過遍布全球的幾百萬輛量産車,可以采集到足夠豐富、足夠多樣的數據,再從中選出優質數據,在雲端使用數萬張 GPU、以及自研的 DOJO 進行訓練和驗證,使得端到端自動駕駛能夠從 paper 變成 product。

到 2023 年初,特斯拉就聲稱已經分析了從特斯拉客戶的汽車中收集的1000萬個視頻片段(clips),特斯拉判斷完成一個端到端自動駕駛的訓練至少需要100萬個、分布多樣、高質量的clips才能正常工作。
特斯拉通過分布在全球的幾百萬量産車,基于影子模式,每當自動駕駛決策與人類司機不一致時,就會采集並回傳一個 clip,已經累積了 200P 以上的數據,不管是數據規模、數據分布還是數據質量上都遙遙領先。爲了能在雲端處理這些數據,當前特斯拉擁有近10萬張A100,位居全球top5,預計到今年底會擁有100EFlops的算力,並針對自動駕駛自研了Dojo,在算力上同樣遙遙領先。
端到端的挑戰比當前帶來的驚喜感要更多。
從特斯拉的開發經驗來看,端到端自動駕駛門檻頗高,其所需的數據規模、算力規模遠遠超出國內企業的承受能力。
