
引言
在生成式AI(GenAI)和大模型時代,不僅需要關注單個GPU卡的算力,更要關注GPU集群的總有效算力。單個GPU卡的有效算力可以通過該卡的峰值算力來測算,例如,對于Nvidia A100,峰值FP16/BF16稠密算力是312 TFLOPS,單卡有效算力約爲~298 TFLOPS [1, 2]。
本篇將聊聊GPU集群網絡配置和GPU集群規模以及總有效算力,重點討論算力網絡平面。因爲存儲和管理網絡平面相對比較簡單,本文就不贅述了。

GPU服務器網卡配置
GPU集群的規模和總有效算力,很大程度上取決于GPU集群網絡配置和使用的交換機設備。對于每一款Nvidia GPU服務器,Nvidia都有對應的推薦GPU集群網絡配置,例如,對于DGX A100服務器,推薦的服務器之間網絡連接是 200 Gbps/卡(即每張A100卡都對應200 Gbps網絡連接與其他服務器中的A100卡通信),單台DGX A100服務器配置8張計算網絡卡(如InfiniBand 200 Gbps)[1, 2]。

那麽GPU服務器之間的計算網絡帶寬是依據什麽來確定的呢?
除了成本因素之外,GPU服務器之間的計算網絡帶寬是由GPU卡所支持的PCIe帶寬決定的,這是因爲GPU服務器配置的計算網絡的網卡是通過PCIe Switch與GPU卡進行連接的(GPU <--> PCIe Switch <--> NIC),那麽PCIe的帶寬就限制了計算網絡的帶寬。
舉例而言,對于Nvidia DGX A100服務器,因爲單張A100卡支持的是PCIe Gen4,雙向帶寬是64 GB/s,單向帶寬是 32 GB/s,即 256 Gbps。所以,爲單張A100卡配置 200 Gbps 的網卡就足夠了。
所以,單看計算網絡,Nvidia DGX A100服務器配置的是8張 Mellanox ConnectX-6 InfiniBand 網卡(注:也可以配置 Mellanox ConnectX-7,因爲ConnectX-7也支持 200 Gbps)。如果是給A100卡配置 400 Gbps 的網卡,因爲受到PCIe Gen4帶寬限制,400 Gbps 的網卡作用是發揮不出來的(那麽就浪費了很多網卡帶寬)。

對于Nvidia DGX H100服務器,因爲單張H100卡支持的是PCIe Gen5,雙向帶寬是128 GB/s,單向帶寬是 64 GB/s,即 512 Gbps。所以,爲單張H100卡配置 400 Gbps 的計算網卡是Nvidia推薦的標准配置 。
單看計算網絡,Nvidia DGX H100服務器配置的是8張 Mellanox ConnectX-7 InfiniBand 網卡,單個H100卡擁有 400 Gbps 對外網絡連接 [5]。

需要說明的是,對于A800和H800服務器的計算網絡配置,國內使用A800和H800服務器一般不是采用Nvidia DGX推薦的標准配置。例如,對于A800服務器,計算網卡配置常見的有兩種方式:第一種是 8 x 200 GbE,即每張A800卡有單獨的200 GbE網卡配置(8張A800卡一共有 ~1.6 Tbps RoCEv2計算網絡連接[7]);
第二種是 4 x 200 GbE,即每兩張A800卡共享一個200 GbE網卡,單卡最高是200 GbE網絡,平均每張A800卡有對外100GbE的連接 [7]。第二種方式類似Nvidia DGX V100的設計 [8]。考慮到可以先在A800服務器內進行通信聚合,然後再與其他服務器通信,所以這兩種計算網卡配置方式對于整個集群效率的影響基本一致。
H800支持PCIe Gen5,對于H800服務器,常見的計算網卡配置方式是 8 x 400GbE,即每張H800卡有單獨的400 GbE網卡配置,每張H800卡都有對外400 GbE的計算網絡連接,8張H800卡一共有 ~3.2 Tbps RoCEv2 計算網絡連接 [7]。
這裏還想談一下華爲昇騰910B NPU卡。
昇騰910B支持PCIe Gen5 [15],也就是說理論上昇騰910B單卡可以配置400 GbE的對外網絡連接。例如,裝配有16卡昇騰910B的服務器一般可以選擇配置 8 x 400 GbE網卡,也就是單卡最高是400 GbE網絡,平均每卡是200 GbE網絡。
華爲昇騰910B采用的是NPU直出200 GbE的設計,所以每個NPU直接連接的是200 GbE的網絡,那麽裝配有16卡昇騰910B的服務器一般配置 16 x 200 GbE網卡,裝配有8卡昇騰910B的服務器一般配置 8 x 200 GbE網卡。
Nvidia使用NVLink和NVSwitch實現了單個服務器內多個GPU之間的高速互聯,而使用多個服務器組建集群時,PCIe帶寬仍然是主要性能瓶頸(集群網絡瓶頸),這是因爲當前網卡和GPU卡之間的連接主要還是通過PCIe Switch來連接。
隨著未來PCIe Gen6(2022年標准發布)普及應用,甚至PCIe Gen7(預計2025年標准發布)普及應用,GPU集群的整體性能又會上一個新台階。還有2024年將要發布的Nvidia H20也是支持PCIe Gen5。
GPU集群網絡和集群規模
上面討論了單個GPU服務器的網卡配置,接下來討論GPU集群網絡架構(GPU cluster fabrics)和集群規模。實踐中最常用的GPU集群網絡拓撲是胖樹(Fat-Tree)無阻塞網絡架構(無收斂設計),這是因爲Fat-Tree架構易于拓展、路由簡單、方便管理和運維、魯棒性好,且成本相對較低。
實踐中,一般規模較小的GPU集群計算網絡采用兩層架構(Leaf-Spine),而規模較大的GPU集群計算網絡采用三層架構(Leaf-Spine-Core)。這裏 Leaf對應接入層(Access),Spine對應彙聚層(Aggregation),Core對應核心層。

假設一個GPU集群的計算網絡裏采用相同的交換機,每台交換機端口數爲P,使用兩層Fat-Tree無阻塞計算網絡(Leaf-Spine),一個GPU集群裏GPU卡的數量最多爲 P*P/2 [9, 14]。
在兩層Fat-Tree無阻塞計算網絡裏(Leaf-Spine),第一層中每一台Leaf交換機用P/2個端口來連接GPU卡,另外P/2個端口向上連接Spine交換機(無阻塞網絡要求向下和向上連接數量相同)。
第二層中每台Spine交換機也有P個端口,可以向下最多連接P台Leaf交換機,所以在兩層Fat-Tree無阻塞計算網絡裏最多有P台Leaf交換機,所以總的GPU卡的數量最多爲P*P/2。因爲有P個Leaf交換機,每台Leaf交換機有P/2個端口向上連接Spine交換機,所以有P/2個Spine交換機。
例如,對于Nvidia A100集群,假設使用40端口的交換機(如Nvidia Mellanox QM8700),在使用兩層Fat-Tree計算網絡情況下,一個A100集群最大可以有800個A100卡(40*40/2 = 800)。
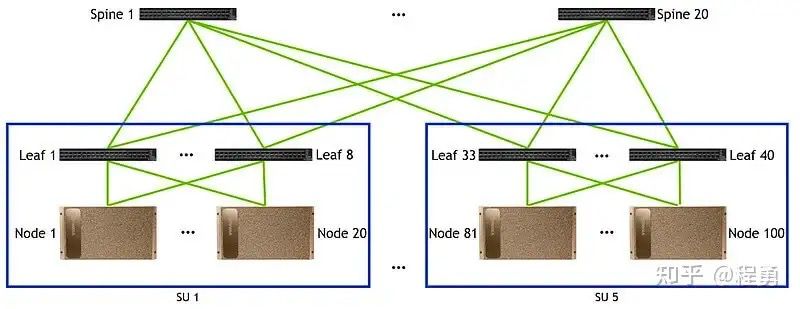
值得注意的是,如果一台GPU服務器內已經有卡間高速互聯了(如NVLink和NVSwitch),則同一台服務器中的GPU卡不應該連接到相同的Leaf交換機上;不同服務器中的編號相同的GPU卡(例如,A服務器中的3號卡 與 B服務器中的3號卡)應該盡量連接到同一個Leaf交換機上,以便提高分布式計算效率(例如,提高跨服務器AllReduce操作的效率)。
需要特別說明的是,對于GPU服務器內沒有卡間高速互聯解決方案的(例如,L20服務器、L40S服務器),需要盡量將一台服務器內的GPU卡連接到同一台Leaf交換機上 [4],以便避開跨NUMA通信。
我們從上面的分析可以看到,假設使用128端口的交換機,兩層Fat-Tree無阻塞計算網絡能夠接入的最大GPU數量僅爲8192(128*128/2 = 8192)。如果要構建更大規模的GPU集群,我們需要從兩層計算網絡擴展到三層計算網絡。
對于規模較大的GPU集群,一般需要采用三層計算網絡架構。
假設一個GPU集群計算網絡裏采用相同的交換機,交換機端口數爲P,對于三層Fat-Tree無阻塞計算網絡(Leaf-Spine-Core),一個GPU集群裏GPU卡的數量最多爲 P*P*P/4 [9, 14]。
從兩層Fat-Tree網絡向三層Fat-Tree網絡擴展,我們可以把兩層Fat-Tree網絡看成一個單元(即一個兩層Fat-Tree子網絡)。因爲每台Spine交換機有一半端口向下連接Leaf交換機(每台Spine交換機最多只能連接P/2個Leaf交換機),另一半端口向上連接Core交換機,所以每個兩層Fat-Tree子網絡裏只能有P/2個Leaf交換機。
在無阻塞網絡裏,各層的連接數量都要保持相同,所以Spine交換機和Leaf交換機的數量相同。
因爲Core交換機也有P個端口,可以連接P個這樣的兩層Fat-Tree子網絡,所以三層Fat-Tree無阻塞計算網絡(Leaf-Spine-Core)中一共有P*P/2個Leaf交換機和P*P/2個Spine交換機,所以GPU卡的總數量最多爲(P/2)*(P*P/2),即 P*P*P/4。Spine交換機向上連接Core交換機的連接數爲P*P*P/4,所以一共有P*P/4個Core交換機。

從上面的分析我們看到,GPU集群的規模是由計算網絡的架構和交換機的端口數決定的(當然,GPU集群規模也受限于機櫃、供電、制冷和機房等硬件因素)。我們在下表中舉例說明集群規模與交換機端口數的關系,以三層Fat-Tree無阻塞網絡爲例。
如果一個服務器內有M個GPU共享一個網卡,則GPU總數量要乘以M。例如,如果一個服務器內的兩個GPU卡共享一個網卡,例如,裝有8卡的A800服務器配置的是 4 x 200 GbE網卡方案,那麽GPU卡的總數量還要乘以2(參考Nvidia DGX V100 [8])。

我們從上面的表格可以看到,基于三層Fat-Tree無阻塞網絡構建的GPU集群,其規模能夠滿足大部分大模型訓練和分布式計算的需求了,所以就不再需要考慮四層或者更複雜的網絡拓撲了。
在上面的分析中,我們假設了整個GPU集群計算網絡都是使用相同的交換機,如果Leaf、Spine、Core分別使用不同的交換機(甚至某一層都可能使用不同的網絡交換機),那麽對于GPU集群網絡和集群規模的分析就變得比較複雜了。
GPU集群算力
一個GPU集群的有效算力可以用下面公式表示:Q = C*N*u。其中,Q表示集群總有效算力;C表示集群中單個GPU卡的峰值算力;N表示集群中GPU卡的數量;u表示集群中GPU卡的算力利用率。這裏,C是指一個計算任務使用N個GPU卡所能獲得的總有效算力。如果使用GPU集群進行大模型訓練,那麽算力利用率u就是我們常說的MFU (Model FLOPS Utilization)。
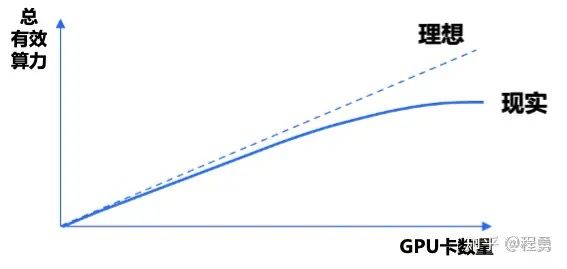
關于算力利用率u,我們要進一步區分算力利用率與線性加速比k。即便是我們在使用單張GPU進行計算,也有算力利用率的問題(相應的,也有顯存利用率的問題,Model Bandwidth Utilization (MBU)[12]),例如,單卡算力利用率 u = 75%。如果一個計算任務裏使用了N個GPU卡,那麽算力利用率u一般會隨著GPU數量N的增加而變小;總有效算力C會隨著N的增加而增加,直到飽和(即N增加的邊際效用遞減)。一個GPU集群的總有效算力C隨著N增加的變化速度就是線性加速比k。
舉例而言,Q1 = C*N1*u1,Q2 = C*N2*u2,那麽 k = (Q2/N2) / (Q1/N1) = u2/u1,這裏假設 N2 >= N1(所以u2 <= u1),且 Q2 >= Q1。
假設理想情況下,單卡算力利用率 u2 = u1,即線性加速比k爲100%,那麽隨著N的增加,集群總有效算力線性增加。這裏線性加速比是說集群總有效算力隨著GPU卡數量增加而變化的情況,假設k爲100%,那就是完美的線性增長。雖然假設線性加速比k爲100%,但是單卡的有效利用率可能會比較低,例如,u2 = u1 = 50%。所以,算力利用率和線性加速比是從兩個不同的維度來描述GPU集群性能。
如果假設 u1 = 45.29%(@N1 = 3584),u2 = 42.19%(@N2 = 10752),那麽線性加速比就是k = 93% [13]。
實踐中,GPU集群的線性加速比受到很多因素影響,包括GPU卡的峰值算力、顯存容量、顯存帶寬、卡間互聯方式、服務器間的網絡帶寬、網絡架構、網絡交換機、軟件和算法等等。在比較好的情況下,一般可以做到線性加速比在90%以上。對于大規模GPU集群,GPU算力利用率一般在50%左右。

-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-

算力的核心是變動。