在當今這個由數據驅動和AI蓬勃發展的時代,數據科學作爲一門融合多種學科的綜合性領域,對于推動各行各業實現數字化轉型升級起著至關重要的作用。近年來,大語言模型技術發展態勢強勁,爲數據科學的進步做出了巨大貢獻。其中,ChatGPT作爲大型預訓練語言模型的代表之一,具備驚人的生成能力,可生成流暢且富有邏輯的文本,其在智能對話、自動寫作、語言理解等衆多領域已取得突破性應用。
作爲數據科學的核心對象和AI發展的基石,數據爲大型預訓練語言模型提供了訓練和優化的依據,通過對大量文本數據的學習,ChatGPT 等模型能夠更好地理解和生成自然語言。因此,如何做好數據治理,發揮數據要素價值,成爲企業競爭優勢的關鍵。
百分點科技與清華大學出版社聯袂打造的《數據科學技術:文本分析和知識圖譜》一書,提供了一個全面而深入的視角,讓我們能夠更好地理解和把握數據科學。書中第十章介紹了以 ChatGPT 爲代表的大語言模型(LLM),詳盡闡述了其發展曆程、現實原理及應用等。以下內容節選自原文:
ChatGPT是由OpenAI基于GPT(Generative Pre-trained Transformer)開發出來的大模型。其目標是實現與人類類似的自然對話交互,使機器能夠理解用戶輸入並生成連貫、有意義的回複。隨著人工智能技術的快速發展,對話系統成爲研究和應用的熱門領域之一。人們渴望建立能夠與人類進行自然、流暢對話的機器智能。傳統的對話系統通常使用規則和模板來生成回複,但在處理更複雜的對話場景時存在局限性。因此,基于深度學習和自然語言處理的對話生成技術逐漸嶄露頭角。
ChatGPT延續了GPT模型的優勢,旨在進一步提升對話系統的自然性和流暢性。它的目標是理解上下文、生成連貫的回複,並在對話交互中創造更真實、有趣的體驗。ChatGPT的研發旨在滿足實際應用中對于對話系統的需求,例如虛擬客服、智能助手等。
ChatGPT的背後支撐著大規模的數據集和強大的計算資源。通過使用海量的對話數據進行預訓練,ChatGPT能夠學習常見的對話模式和語言表達方式。同時,ChatGPT的開發者借助雲計算和分布式技術,建立了龐大的計算集群來訓練和優化模型。這種大規模計算能力對于提升ChatGPT的生成質量和實時性發揮重要作用。
ChatGPT的預訓練和微調
GPT大模型通過預訓練已經學習了許多技能,在使用中要有一種方法告訴它調用哪種技能。之前的方法就是提示模版(Prompt),在GPT-3的論文裏,采用的是直接的提示模版和間接的Few-Shot示例。但是這兩種方法都有問題,提示模版比較麻煩,不同的人表達相似的要求是有差異的,如果大模型要依賴各種提示模版的魔法咒語,那就和煉丹一樣難以把握。
ChatGPT選擇了不同的道路,以用戶爲中心,用他們最自然的方式來表達需求,但是模型如何識別用戶的需求呢?其實並不複雜,標注樣本數據,讓模型來學習用戶的需求表達方式,從而理解任務。另外,即使模型理解了人類的需求任務,但是生成的答案可能是錯誤、有偏見的,因此還需要教會模型生成合適的答案,這就是人類反饋學習,具體而言,這種反饋學習方法包括如下三步:
模型微調Supervised Fine-tuning(SFT):根據采集的SFT數據集對GPT-3進行有監督的微調(Supervised FineTune,SFT);這裏本質上是Instruction-tuning。
訓練獎勵模型Reward Modeling(RM):收集人工標注的對比數據,訓練獎勵模型(Reword Model,RM);
強化學習Reinforcement Learning(RL):使用RM作爲強化學習的優化目標,利用PPO算法微調SFT模型。
接下來的內容中,對這三個步驟進行具體闡述。
1. 模型微調SFT
在ChatGPT中,SFT通過對模型進行有監督的微調,使其能夠更好地適應特定任務或指導。在模型微調的過程中,需要准備一個有監督的微調數據集。這個數據集由人工創建,包含了輸入對話或文本以及期望的輸出或回複。這些期望的輸出可以是由人工提供的正確答案,或者是由人工生成的合適的回複。
接下來,根據這個有監督的微調數據集,我們對GPT模型進行微調。微調的過程可以通過反向傳播和梯度下降算法實現,它們使得模型能夠通過調整參數來更好地擬合數據集。在微調過程中,模型會根據輸入對話或文本産生預測的輸出或回複,並與期望的輸出進行比較,計算損失函數。然後,通過最小化損失函數,模型會逐步調整參數,以使預測結果更接近期望輸出。
微調之後,ChatGPT模型將能夠更好地執行特定的任務,因爲它在有監督的過程中學習到了任務的知識和要求。而這個有監督的微調過程本質上也是Instruction-tuning的一種形式,因爲它可以根據人工提供的指導或期望輸出來調整模型,具體步驟如圖10-7所示。

ChatGPT模型訓練步驟1
2. 訓練獎勵模型RM
在ChatGPT中,通過收集人工標注的對比數據來訓練一個獎勵模型,用于指導GPT模型的優化過程,如圖10-8所示。
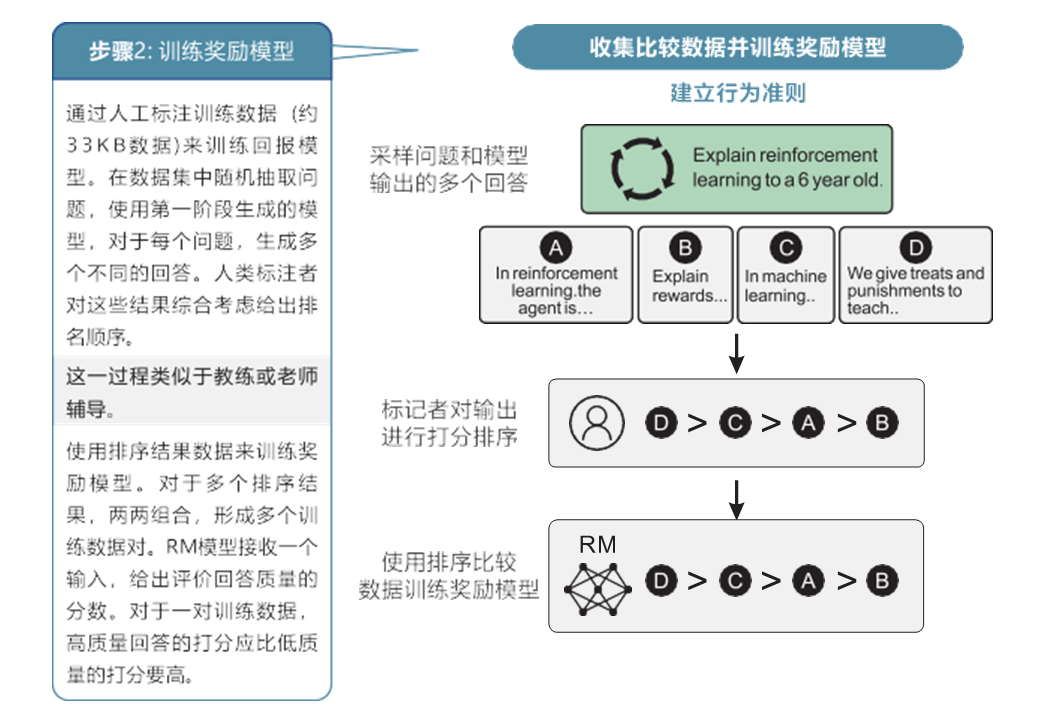
ChatGPT模型訓練步驟2
爲了訓練獎勵模型,我們需要准備一組對比數據。對比數據由人工創建,包含了多個對話或文本的對比實例,每個對比實例包含兩個或多個不同的模型回複。人工對這些回複進行標注,給出每個回複的質量或好壞的評分。
接下來,我們使用對比數據訓練獎勵模型。獎勵模型可以是一個分類模型,也可以是一個回歸模型,它的輸入是對話或文本的特征表示,輸出是一個評分或獎勵。獎勵模型的目標是根據輸入的對話或文本來預測模型回複的質量。
使用訓練好的獎勵模型,我們可以對GPT模型的回複進行評分,得到一個獎勵值。這個獎勵值可以用作強化學習的優化目標,以指導GPT模型在後續的對話中生成更優質的回複。
3. 強化學習RL
在ChatGPT中,強化學習是一種反饋學習方法,利用獎勵模型作爲強化學習的優化目標,通過使用PPO算法來微調SFT模型。
強化學習通過與環境的交互來學習一種策略,使得模型能夠在給定環境下采取最優的行動。在ChatGPT中,環境可以看作是對話系統的對話環境,模型需要根據輸入的對話來生成回複,並受到獎勵模型提供的獎勵信號的指導。
在強化學習中,我們使用PPO算法(Proximal Policy Optimization)來微調SFT模型。PPO算法是一種在強化學習中常用的策略優化算法,旨在尋找最優的行動策略,如圖10-9所示。

ChatGPT模型訓練步驟3
首先,我們使用SFT模型生成對話回複。然後,使用獎勵模型對這些回複進行評分,得到一個獎勵值。這個獎勵值可以指示模型回複的質量和適應度。
接下來,利用PPO算法來微調SFT模型。PPO算法采用基于策略梯度的優化方法,通過最大化期望回報或獎勵來更新模型的參數。具體來說,PPO算法使用短期的策略梯度優化模型的策略,以獲得更好的回報。通過不斷叠代這個過程,模型的策略會逐漸改進,生成更優質的對話回複。
在強化學習中,模型會通過與環境(對話環境)的交互來學習,根據獎勵模型提供的獎勵信號和PPO算法中的策略梯度更新方法不斷調整模型的參數。模型的目標是找到一種策略,使得在給定對話環境下,生成的回複能夠獲得最大化的獎勵或回報。
通過以上三個步驟:模型微調(SFT)、訓練獎勵模型(RM)、強化學習(RL),ChatGPT可以通過反饋學習方法不斷優化和提升,使其在生成對話回複時更准確、合理和人性化。這種反饋學習方法的應用,可以使ChatGPT具備更強的適應性和可控性,讓其適應不同的任務和場景,並根據用戶的反饋不斷改進和提升自身的表現。
ChatGPT是數據科學領域具有革命性和劃時代意義的裏程碑技術,展望未來,其爲大數據和人工智能等技術的新突破、新發展帶來無限機遇與挑戰。
————————————
關注百分點科技官網,了解更多數據科學相關技術與實踐。
書籍背景:本書由百分點科技與清華大學出版社聯合出版。百分點科技成立于2009年,是領先的數據科學基礎平台及數據智能應用提供商,總部位于北京,在上海、沈陽、深圳、廣州、武漢、濟南、香港等地設有十八家分子公司,業務覆蓋全球多個國家和地區。百分點科技以“用數據科學構建更智能的世界”爲使命,爲政府和企業提供端到端的場景化解決方案,在數字城市、應急、公安、統計、生態環境、零售快消、媒體報業等多個領域,助力客戶智能化轉型。百分點科技是國家高新技術企業、北京市企業科技研發機構、全國信標委大數據標准工作組&人工智能分委會成員單位。
