Key Points
外界稱Perplexity爲「AI搜索」,它更喜歡自稱「答案引擎」;
Perplexity團隊中不少成員來自Quora,Perplexity本身也很像一個AI版知乎;
「微調」還是「搜索增強」?市場已分爲兩大陣營;
Perplexity的産品哲學:1.用戶永遠不犯錯;2.把産品做深;
創業前,Perplexity創始人在Google和OpenAI都實習工作過;
OpenAI已開發類似産品,傳聞本周就會上線。
Perplexity,這個翻譯成中文叫作「困惑」的産品很受歡迎已經不是新聞了。
英偉達創始人黃仁勳不久前接受采訪時聲稱,他「每天都會用Perplexity」。今年1月,這家公司聲稱自己的月活躍用戶已超過1000萬,僅印度就有超過100萬用戶。而今年迄今爲止,Perplexity在美國市場收到的用戶查詢接近7500萬單,比2023年全年都要多。4月23日的最新一輪融資中,它籌集了約6300萬美元資金,估值超過10億美元——僅僅3個月前,其估值還只有5億美元。
Perplexity正在改變傳統的搜索體驗。自2022年8月推出以來,曾在Google人工智能部門任職的研究人員在短短的時間內就研發出了一個聊天機器人式的研究助理,用戶可以向其提問,該助理將實時回應從互聯網獲取的信息,以及它使用的信息來源。
最新傳聞稱,OpenAI已開發類似産品,並且本周就會上線。除了OpenAI,阿裏巴巴旗下的搜索引擎品牌誇克據說也准備在今年下半年推出有類似用戶UI的搜索産品,中國初創公司中的智譜、豆包、月之暗面都已爲自己的問答機器人加入了提供參考鏈接功能——智譜不僅給出了參考鏈接,還像Perplexity那樣在回答完問題後列出了一些「相關問題」,此外,它也效仿Perplexity開始將當日新聞作爲話題,展示在對話框的上方。

答案引擎
模型「聰明」並不是Perplexity的最大賣點,畢竟它使用的都是第三方模型,其中既有GPT也有Gemini和Claude,有人因此甚至把它歸爲「套殼」産品。不過它吸引用戶的關鍵之一恰恰是産品設計。
乍一看,它也像一個聊天機器人,提供與ChatGPT類似的交互體驗。你向它提出一個問題,比如問它馬斯克的腦機接口是怎麽回事,它就會回答你「馬斯克是Neuralink公司的創始人,而這家公司不久前宣布了全世界第一起腦機接口的人體試驗,該人體試驗的初步結果顯示,這個植入人腦的設備探測到了神經元的放電模式」。
不過,相較其他聊天機器人,Perplexity提供了一個新東西——確定性。比如,它會在所生成內容的某些關鍵信息後面添加數字小標,然後像論文格式那樣列出信息來源。循著小標,你就能看到路透社、彭博社、CNN、雅虎、連線等知名媒體關于Neuralink公司的腦機接口人體試驗的原版報道鏈接。
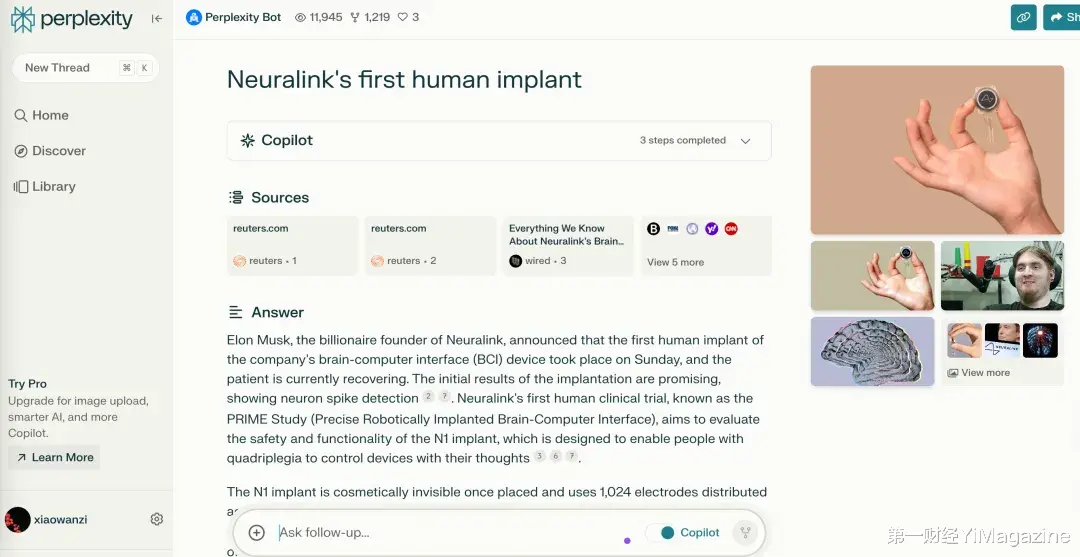
而在AI回答的下方,你還能看到一系列相關問題,比如「Neuralink開發腦機接口的目的是什麽」「Neuralink的腦機接口如何工作」或者「Neuralink腦機接口的潛在風險是什麽」。這些問題被稱作「相關問題」(follow-up question),如果它們引發了你進一步了解的興趣,你可能就會點進去繼續閱讀——這個設計聽起來有點像AI版的知乎,只不過提供回答的不是人類,而是AI。
除此之外,它還提供一種非常有用的功能,即允許用戶將搜索範圍限制在特定數據庫中,比如你可以要求它將檢索範圍限定爲YouTube、Reddit,也可以是特定學術期刊。
像Perplexity這種産品在市面上被稱爲「AI搜索」,因爲它在回答問題之前其實先去搜索引擎上搜索了一圈相關信息,然後才歸納總結並回複用戶。不過,Perplexity創始人兼CEO Aravind Srinivas更願意稱之爲「答案引擎」(Answer Engine)。「用戶可以直接提出任何問題,並得到一個實際的答案,而不僅僅是一個可能包含或不包含答案的網頁列表。」Aravind Srinivas說。
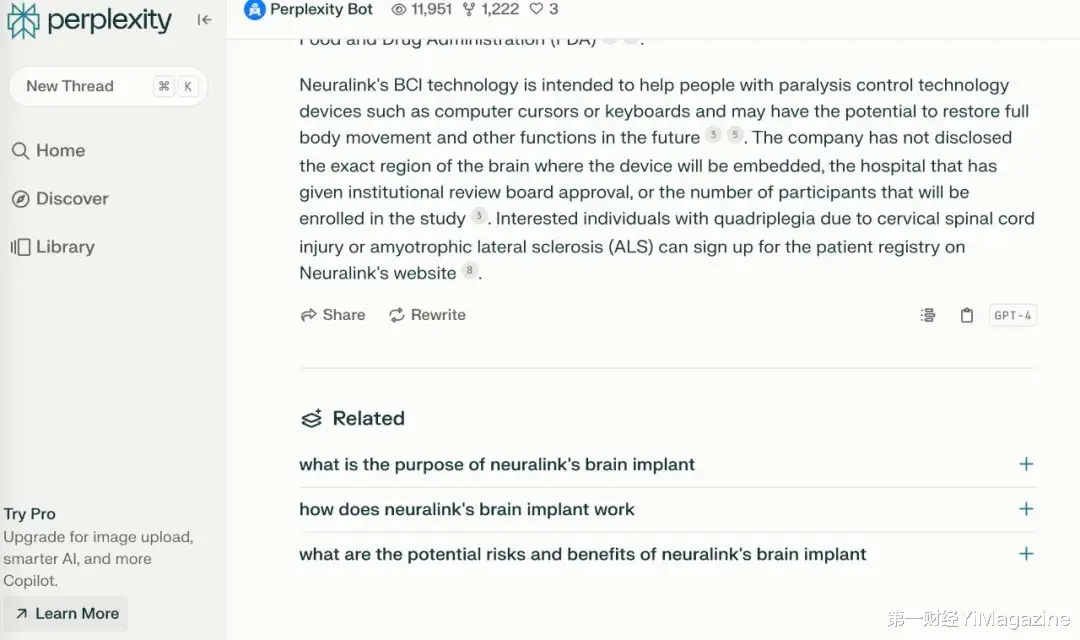
回答完你的提問,它還會給出一系列「相關問題」,答案同樣是AI生成的。
答案引擎、問答系統的曆史其實比搜索引擎更古老。早在Google的網頁列表式UI出現之前,1970年代,信息檢索領域的研究者就開始制作一種通過自然語言處理(NLP)來訪問文本的應用程序。1990年代中期出現的Ask Jeeves服務(現爲Ask.com),就是以一個穿著考究的人類形象,在網頁中提供問答服務。

1990年代,Ask公司就開始以一個Jeeves的形象提供問答服務(現爲Ask.com)。
2020年左右,Google也曾探索過通過簡單的文本提取方式實現問答服務,如今你在Google搜索某一新聞或其他事物後出現的幾百字摘要,就是這種文本提取技術的成果。不過沒有大模型技術,這種文本提取式問答無法綜合多個頁面的內容,也因此無法回答更爲複雜的問題。
RAG:一種開卷考試
讓Perplexity不同于Google的是答案引擎,而讓Perplexity不同于ChatGPT的,是被稱作RAG(Retrieval-Augmented Generation)的檢索增強生成技術。顧名思義,這種技術使大型語言模型(LLMs)可以連接到外部知識庫,利用從外部來源獲取的事實提高生成式AI模型的准確性和可靠性,減少模型本身的「幻覺」。
創造RAG這個詞和技術的人是帕特裏克·劉易斯 (Patrick Lewis) ,他在2020年一篇名爲《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》的文章中首次提出了這種方法。現在,他是Cohere RAG團隊的負責人。

RAG技術可以與任何外部數據源連接,通過它,用戶基本上可以與任何數據存儲庫對話。比如,醫療領域的聊天機器人可以通過查詢醫院數據成爲醫生的得力助手,金融分析師的機器人也可以通過查詢市場相關數據庫變得更爲可靠。
幾乎每家企業都有屬于自己的知識資産、數據庫,過去,以OpenAI爲代表的大模型公司提出以「微調」的方式爲各垂直領域客戶提供服務,即它倡導用各企業的內部數據繼續訓練大模型公司們提供的基礎模型,從而推出一個更懂某家公司的專有模型。舉個例子,GPT-4在學習了更多法律、財務知識後,就比在這些領域學得不夠多的GPT-3.5更容易通過司法考試、分析師考試。
而RAG的路徑與此不同,采用這種技術的公司,比如Perplexity,沒有讓GPT-3.5或GPT-4繼續學習特定領域的垂直知識,而是將這部分數據作爲可隨時查詢的對象給模型參考。打個比方,OpenAI不斷用更多數據訓練學識更淵博的大模型、然後由其直接爲用戶解答的做法相當于一種閉卷考試,Perplexity之類的RAG公司則是開卷考試。
「用戶永遠不犯錯」
産品形態上,Perplexity位于搜索引擎Google和聊天機器人ChatGPT之間,除了問答窗口、「相關問題」,它還有一個叫「發現」(Discover)的選項卡,裏面有大量人爲選擇的當日新聞摘要供用戶浏覽和繼續追問。與ChatGPT或Gemini相比,「發現」選項卡使得用戶了解全球正在發生的新聞變得更加容易。

「發現」選項卡展示了人工編輯選出來的當天熱門新聞。
整體看起來,Perplexity更像一個AI版的知乎,用戶哪怕不提出問題,也能看到足夠多且有趣的問答。
Perplexity身上有知乎的影子似乎並不令人意外,因爲其創始團隊中的多位成員都曾在Quora工作,後者是一個問答社區,知乎曾經模仿的正是Quora。比如Denis Yarats,他曾在Quora擔任機器學習工程師,如今,他是Perplexity的CTO;創始設計師Henry Modisett也曾在Quora工作超過8年,曾參與設計Quora的feed流、問答等産品設計。
Quora創立于2009年,是一個基于知識分享的社交網絡。
不過,Perplexity創始人Aravind Srinivas並沒有在Quora工作過,促使他采納「AI問答社區」這一設計方案的哲學有兩個:其一,用戶不會有犯錯;其二,無論如何都不要單純做搜索。
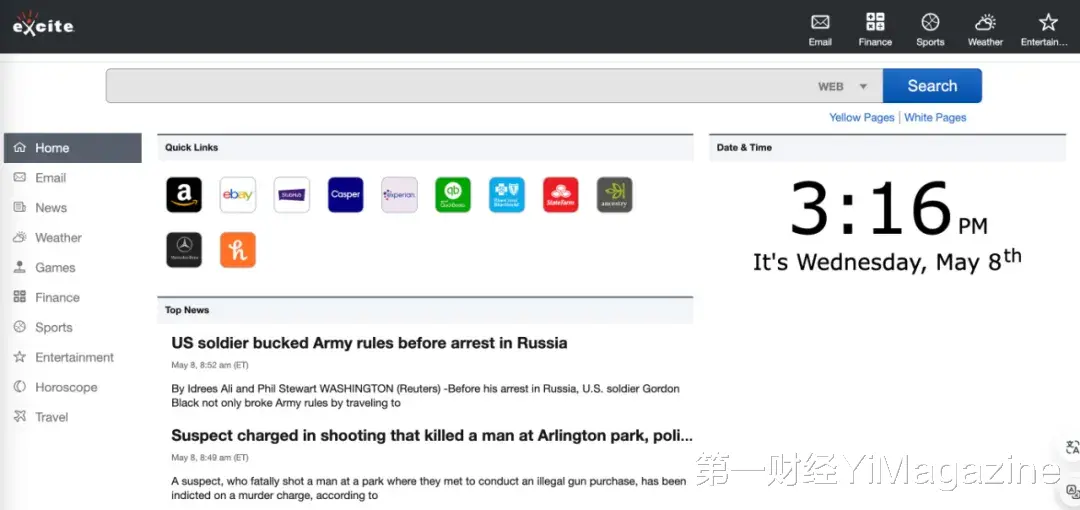
第一個産品哲學來自他的競爭對手Google。Aravind Srinivas稱,他看過Google聯合創始人拉裏·佩奇(Larry Page)分享的一個故事:佩奇和Google另一位聯合創始人謝爾蓋·布林(Sergey Brin)曾經差點把Google賣給Excite,當時他們一起給Excite CEO做了演示,同時打開兩個浏覽器窗口,一個是Google,另一個是Excite,然後佩奇在兩個搜索引擎中輸入了同樣的文字,Google成功返回了相關鏈接,而Excite沒有。Excite的人當場表示Excite沒有成功返回鏈接是因爲佩奇的輸入「不准確」。佩奇回答「我只是個用戶,我沒有犯錯」。從這個故事中,Aravind Srinivas學習到了人機交互的一個基本原則——用戶永遠不犯錯。
「雖然每個人都有很強的好奇心,但能將好奇心轉化爲精確問題的人很少。」Aravind Srinivas說,Perplexity因此花了大量時間在處理、分析和重組用戶查詢的問題上,也就是說,當用戶提出相對含糊的問題後,Perplexity會首先將問題處理成更有邏輯的提問方式,即優化用戶的Prompt後,才將問題交給模型回答。
「相關問題」和「發現」功能的設計也出于同一邏輯,Aravind Srinivas稱,他會親自參與「發現」選項卡背後的內容挑選,以便持續了解産品是否一直「足夠簡單,連普通新用戶都能輕松理解」。Perplexity首席商務官Dmitry Shevelenko提供的數據稱,由「相關的問題」産生的用戶查詢占據Perplexity總查詢量的40%。
持續改進産品,讓現有用戶不斷把産品推薦給更多朋友使用,同時保持産品容易上手的特性,對新用戶友好。Aravind Srinivas稱這兩點也是Facebook早期的用戶增長策略。

Perplexity三位聯合創始人Aravind Srinivas、Denis Yarats、Johnny Ho。
「無論如何都不要單純做搜索」,這個哲學是投資人Marc Andresson給Aravind Srinivas的建議。Aravind Srinivas曾一度迷茫是不是應該專注做垂直搜索引擎,而不是把業務繼續擴展到AI問答社區等有社交屬性的領域。Marc Andresson的回答是「大多數宣稱做垂直領域Google的公司都失敗了,反而是在垂直領域建立端到端用戶體驗的公司成功了」,比如Booking,它不僅能搜索酒店,還能直接完成預訂,而Airbnb已經不只是一個住宿預訂平台,而是一家能提供綜合旅行服務的公司了。只要做得足夠深,競爭優勢就不會只停留于技術、用戶積累這樣的單點上。
Aravind Srinivas被Marc Andresson說服。如果Perplexity的初衷是滿足人們無窮的好奇心,那一個AI版問答社區就會比單純的搜索引擎有用得多。「在Quora上,人們需要花一定時間等待別人來回答自己的提問,不僅很慢,也無法最大化加速知識的獲取,Perplexity就是想要解決這樣的問題。」Aravind Srinivas說。
Perplexity正在追求成爲「服務更加全面」的公司。除了網頁端産品,它最近還推出了適配蘋果Vision Pro的頭顯端應用程序,並與Brilliant Labs建立了合作夥伴關系,用戶能通過AR眼鏡完成查詢。
積累用戶比訓練模型重要
和曾經激勵Aravind Srinivas創業的Jasper一樣,Perplexity也一度被質疑爲大模型的「套殼」産品,因爲它在很長時間裏都沒有訓練自有模型,而是利用GPT、Claude等第三方模型向用戶提供基于AI的搜索服務。
不過Aravind Srinivas堅信他的做法才是對的,「如果你的目標是建立以産品爲核心的公司,就不要在訓練自有模型上浪費時間」,他認爲「成爲一個擁有10萬用戶的套殼産品顯然比擁有自有模型卻沒有用戶更有價值」。直到Meta發布第二代模型Llama 2並開源後,Perplexity才開始基于這一開源模型訓練自有模型。
直到現在,Perplexity的團隊規模都不大,只有45名員工,總部位于舊金山的一個共享辦公空間。
4月初,Perplexity表示其活躍用戶已經增長到1500萬,比1月報告的1000萬增長了50%。但Srinivas和他的投資者認爲,顛覆Google搜索的時機已經成熟。
Perplexity被認爲是Google的強有力潛在競爭者。咨詢公司Gartner預測,到2026年,傳統搜索引擎的市場將下降25%。因爲搜索營銷的份額會被ChatGPT那樣的聊天機器人、Perplexity這樣的答案引擎,或者其他AI智能體(agent)奪走。
Google已在測試自己的的生成式搜索工具,不過態度似乎不夠堅定——就連這項AI搜索的名字本身「Search Generative Experience」(搜索生成體驗),聽起來也毫不響亮。
商業模式上的挑戰是Google一直難以跳下來做「問答引擎」的原因。自2000年以來,Google的主要收入來源就是廣告。根據Google 2023年財報,其廣告業務營收2378.6億美元,在總營收中占比77.4%。如果生成式AI能夠對于用戶提問給出快速且完整的回答,可能使得傳統搜索引擎和夾雜在網頁列表中的高利潤廣告變得多余。
Perplexity面臨的商業化挑戰與Google其實是一樣的。其網站上目前還沒有廣告,因爲它認爲搜索應該「不受廣告驅動模式的影響」,但它打算在「相關問題」中提供有品牌贊助的問題。這一廣告産品可能在未來幾個季度推出,能創造多少廣告收入還是未知數。
目前,Perplexity的主要盈利方式是對高級功能收費。和OpenAI、Anthropic等公司一樣,如果用戶想要訪問平台上的高級功能,比如上傳自己的文件,讓模型根據自己的職業、位置、好惡等信息來創建「個人資料」,以獲得個性化的答案和建議,就要支付20美元/月的訂閱費。爲這些高級功能付費的用戶並不多,自2022年12月推出以來,只有不到10萬人爲高級版付費。
公司檔案:
Perplexity

創始人AravindSrinivas:
2017年,在印度理工學院馬德拉斯分校獲得工程碩士學位。
2018年年中,在OpenAI實習,專注于使用策略梯度算法解決強化學習問題。
2019年年中,在DeepMind實習了大約5個月,專攻大規模對比學習。
2020年5月至2021年4月,在Google實習,參與研發基于自我注意力的模型HaloNet和SOTA視覺模型,如ResNet-RS。
2021年,獲得加州大學伯克利分校的計算機科學博士學位。除了強化學習,他還專注于計算機視覺、圖像識別、視頻生成和圖像生成的Transformer的對比學習。
2021年9月,回到OpenAI擔任研究科學家,從事語言和擴散生成模型研究。
2022年8月,離開OpenAI,並于當月創辦Perplexity AI。
2022年11月,ChatGPT上線。
2022年12月,Perplexity上線。
Perplexity融資:
2022年9月,獲310萬美元融資(種子輪),Google首席科學家Jeff Dean、GitHub前CEO Nat Friedman、OpenAI聯合創始人Andrej Karpathy和天使投資人Elad Gil參與投資。
2023年3月,獲2560萬美元融資(A輪),估值1.5億美元。2024年1月,獲7360億美元融資(B輪),IVP領投,亞馬遜創始人貝索斯參投。公司估值5.2億美元。
2024年4月,約獲6300萬美元融資,估值超過10億美元。
