報告出品方:東吳證券
以下爲報告原文節選
------
一、如何看待OEM自研智駕芯片?
芯片分類:四類主流芯片覆蓋市場不同應用場景
當前市場上流通的主流芯片包括四大類:1)處理器芯片,包括CPU、GPU、DSP、和MCU,負責系統的運算和控制核心,以及信息處理和程序運行的最終執行單元。2)存儲器芯片:包括靜態(SRAM)以及動態(DRAM)隨機存取存儲器等,用于數據的存儲。3)模擬-數字轉換器(ADC) 和 數字-模擬轉換器 (DAC):這兩種芯片分別用于模擬信號和數字信號的互相轉換,廣泛應用于傳感器和測量儀器中。4)片上系統(SoC):集成微控制器/處理器/存儲器/通信接口和傳感器等元件,通過簡單編程可以實現豐富的功能。
AI芯片是屬于SoC片上系統芯片的特殊分支,是指針對人工智能算法做了特殊加速設計的芯片,專門用于處理人工智能應用中的大量計算。

AI芯片分類:GPU以及ASIC主導訓練/推理應用
爲滿足行業發展對于芯片處理性質單一但規模龐大的數據計算的需求,産業基于GPU圖像處理器的並行計算能力持續升級,開發了以極致性能爲代表的GPU以及以極致功耗爲代表的ASIC芯片,以及介于二者之間,兼具靈活性和高性能的FPGA等不同類型芯片,應用于包括雲端訓練以及邊緣段推理等不同場景。未來,AI芯片將持續叠代,開發高度模擬人腦計算原理的類腦芯片,圍繞人腦的神經元/脈沖等環節,實現計算能力的飛躍提升以及能耗的大幅下降。

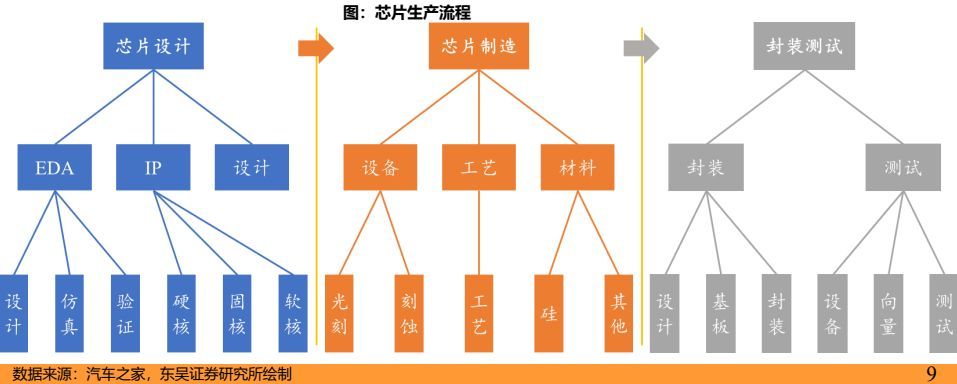
芯片生産:設計爲基礎,制造最核心,封測保性能
芯片制造分爲三大步驟,分別是芯片設計、芯片制造、封裝測試
➢ 芯片設計:在EDA軟件工具的支持下,通過購買授權+自主開發獲得IP,遵循集成電路設計仿真驗證流程,完成芯片設計。首先明確芯片目的(邏輯/儲存/功率),編寫芯片細節,形成完整HDL代碼;其次利用EDA軟件(高制程工藝軟件市場集中度高)將HDL代碼轉爲邏輯電路圖,進一步轉爲物理電路圖,最後制作成光掩模。
➢ 芯片制造:壁壘最高!三大關鍵工序光刻、刻蝕、沉積,在生産過程中不斷重複循環三工序,最終制造出合格的芯片。過程中要用到三種關鍵設備,分別是光刻機、刻蝕機、薄膜沉積設備。
➢ 封裝測試:測試是指在半導體制造的過程中對芯片進行嚴格的檢測和測試,以確保芯片的質量和穩定性和性能;而封裝則是將測試完成的芯片進行封裝,以便其被應用在各種設備中。
設計環節:EDA軟件格局集中,IP模塊是核心産權
EDA:(Electronic Design Automation)電子設計自動化,常指代用于電子設計的軟件。目前,Synopsys、Cadence和Mentor(Siemens EDA)占據著90%以上的市場份額。在10納米以下的高端芯片設計上,其占有率甚至高達100%。國産EDA工具當前距離海外龍頭有較大差距。
IP核:指一種事先定義、經過驗證的、可以重複使用,能完成特定功能的模塊(類似于excel模板),物理層面是指構成大規模集成電路的基礎單元,SoC甚至可以說是基于IP核的複用技術。
其包括處理器IP(CPU/GPU/NPU/VPU/DSP/ISP…)、接口IP(USB/SATA/HDMI…)、存儲器IP等等幾類。對于當前智駕領域AI芯片而言,常用IP核包括CPU、GPU、ISP、NPU、內存控制器、對外接口(以太網【用于連接不同車身設備以交換數據】和PCIe接口【用于主板上的設備間通訊】)等。

制造環節:設備/工藝/材料多環節,高壁壘高集中度
芯片制造三大關鍵工序:光刻、刻蝕、沉積,三大工序在生産過程中不斷循環,最終制造出合格的芯片;其中,設備+工藝+材料等環節尤爲關鍵;芯片制造以台積電、三星、英特爾寡頭壟斷。
➢ 設備:三大關鍵工序要用到光刻機、刻蝕機、薄膜沉積設備三種關鍵設備,占所有設備投入的22%、22%、20%左右,是三種難度和壁壘最高的半導體設備。
➢ 工藝:芯片制造需要2000道以上工藝制程,主要包括光刻、刻蝕、化學氣相沉積、物理氣相沉積、離子植入、化學機械研磨、清洗、晶片切割等8道核心工藝。
➢ 材料:硅晶圓和光刻膠是最核心的兩類材料,90%以上的芯片在硅晶圓上制造,光刻膠是制造過程最重要的耗材,半導體光刻膠壁壘最高,全球CR5接近90%。

底軟以及工具鏈開發是自研智駕芯片的後端壁壘
異構計算架構/生態開發環境:以英偉達CUDA和華爲CANN爲代表的核心軟件層,用于調度AI芯片和通用芯片的底層算子,並針對性地進行加速和執行,更好地發揮出芯片的算力,實現效率最大化。
SDK軟件開發工具包(Software Development Kit):是指軟件工程師爲特定的軟件包、軟件框架、硬件平台、操作系統等建立應用軟件時的開發工具的集合;借助SDK,應用開發者可以迅速基于特定平台開發差異化上層應用。

智駕芯片自研聚焦設計環節中的IP核:NPU/ISP等
智駕邊緣端芯片以自研NPU爲主,塑造産品差異化。
智駕SoC芯片以CPU中央處理器+GPU圖形處理器+DSP數字信號處理器+ISP圖片處理器+NPU(AI計算單元)以及I/O接口以及存儲器等IP核集成組裝而成,其中NPU/CPU/ISP等環節對智駕邊緣段數據處理更爲重要。産業鏈玩家自研智駕芯片即指芯片自主設計IP核,尤其是NPU,其次ISP等,CPU以及GPU多以外采ARM/英偉達等爲主,技術相對成熟,其余I/O接口以及存儲器同樣依賴外部采購。
雲端芯片多采用集中外采形式,主要系雲端芯片對于能耗以及CPU/GPU綜合能力要求較低,僅對強AI算力也即單一GPU/NPU的計算能力有較高需求,規模效應是核心優勢,外部方案更成熟。


邊緣端:自研芯片勢在必行,強化軟硬件適配提效
智能駕駛産品力的競爭短期看産品體驗,中期看叠代效率,長期看降本能力。
➢ 1)短期——算力強冗余階段:産品體驗取決于軟件算法成熟度(背後是數據量爲支撐),與智駕芯片自研相關性較低,高通/英偉達/華爲/地平線等多家第三方供應商産品均可滿足。
➢ 2)中期——算力提效階段:在保有量提升帶動數據飛躍增長後,前期冗余布局的邊緣端硬件的利用效率進一步提升,同時也對底軟更好地調用芯片算力提出更高要求,自研芯片NPU/ISP等核心環節的優勢顯現,叠代速率更快。
➢ 3)長期——協同並進階段:足量數據餵養下軟硬件能力協同提升,保障功能體驗的同時優化成本結構,要求玩家對底層硬件具備全棧深入了解。

雲端:自研利好數據閉環增效,一體化整合更優
雲端芯片自研有利于數據全流程閉環,提升數據利用率和算法叠代速率,但同時成本負擔較大。
➢ 智駕數據量指數級增長驅動智駕功能升級,數據的存儲、優化、利用、訓練等各環節對雲端訓練/傳輸等要求較高,“數據驅動”的智駕叠代模式下,數據閉環的模型訓練與AI計算平台相互賦能,同時提升多元異構數據的清洗和標注效率,有利于提升算法叠代升級速率。
➢ 雲端超算中心芯片與邊緣端芯片不同,其能力依賴GPU/NPU等的單一計算能力,前期研發和中期運維以及後期應用部署成本均較高,需要強大規模效應進行攤薄。

可行性分析:對照地平線/黑芝麻,芯片自研可爲
對照國內智駕芯片初創企業地平線、黑芝麻智能等公司芯片自研曆程,【千人研發規模;30~50億研發投入;2~3年耗時】可完成智駕芯片全自研以及配套解決方案落地:
地平線:自2015年成立至2024年,公司累計融資171億元人民幣,創收30億元以上,截至23年底在手現金114億元,已完成涵蓋L2/L3級別SoC芯片和配套工具鏈/底軟等的開發和規模量産。
黑芝麻智能:自2017年成立至2024年,累計融資30億元人民幣,創收4.5億元以上,截至22年底在手現金不足10億元,同樣完成L2級SoC智駕芯片(NPU/ISP)等IP核自研開發和規模量産。
➢ 研發耗時:1)地平線2015年成立,2019年首款智駕芯片落地;2024年預計落地征程6系列支持L3級別芯片;2)黑芝麻智能2017年成立,2019年首款智駕芯片落地,2024年大算力落地。
➢ 團隊規模:截至2023年底,地平線/黑芝麻智能研發團隊人數分別有1478/950人。
➢ 資金投入:地平線2021年至2023年,研發費用累計投入54億元,黑芝麻智能2020年至2023年研發費用累計投入30億元,大額研發投入保證智駕芯片持續叠代升級。

二、第三方玩家自研智駕芯片成效如何?
廠商布局比較:英偉達/特斯拉最全,其余快速跟進
綜合OEM主機廠以及Tier環節供應商,我們梳理自研智駕芯片並已有或即將有成熟産品量産出貨的玩家進行橫向對比:英偉達/特斯拉目前雲端&邊緣端芯片硬件以及對應底軟&工具鏈布局最爲完善,高通聚焦邊緣端自研&Tier1落地模式迅速落地,地平線/黑芝麻智能由低到高布局。

2.1、英偉達:高舉高打,算力+生態最強音
發展曆程:由GPU起構建軟硬件壁壘,拓展全行業
英偉達成立于1993年,由黃仁勳聯合Sun公司兩位年輕工程師共同創立。最初致力于GPU的研發,1999年成功上市。隨著GPU在圖形和高性能計算領域的成功,英偉達逐漸擴展至人工智能、深度學習、自動駕駛和醫療等領域。公司的GPU技術在科學計算、遊戲和專業工作站等領域取得巨大成功,成爲全球領先的半導體公司之一。

CUDA:更好加速GPU計算,構建英偉達生態壁壘
CUDA 是 NVIDIA 發明的一種並行計算平台和編程模型,全稱Compute Unified Device Architecture它通過更好地調用圖形處理器 (GPU) 的處理能力,對算法運行進行加速,可大幅提升計算性能,並構建英偉達自身的軟件生態。CUDA的優勢在于:1)並行計算:CUDA允許開發者使用GPU的大量核心進行並行計算,以加速各種計算密集型任務;2)高效內存管理:CUDA提供了高效的內存管理機制,包括全局內存、共享內存、常量內存等,可以最大限度地利用GPU的內存資源;3)強大的工具支持:CUDA提供了一系列強大的工具支持,包括CUDA編譯器、CUDA調試器、CUDA性能分析器等,可以幫助開發者更加高效地開發和調試CUDA程序。

--- 報告摘錄結束 更多內容請閱讀報告原文 ---
報告合集專題一覽 X 由【報告派】定期整理更新
(特別說明:本文來源于公開資料,摘錄內容僅供參考,不構成任何投資建議,如需使用請參閱報告原文。)
精選報告來源:報告派科技 / 電子 / 半導體 /
人工智能 | Ai産業 | Ai芯片 | 智能家居 | 智能音箱 | 智能語音 | 智能家電 | 智能照明 | 智能馬桶 | 智能終端 | 智能門鎖 | 智能手機 | 可穿戴設備 |半導體 | 芯片産業 | 第三代半導體 | 藍牙 | 晶圓 | 功率半導體 | 5G | GA射頻 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圓 | 封裝封測 | 顯示器 | LED | OLED | LED封裝 | LED芯片 | LED照明 | 柔性折疊屏 | 電子元器件 | 光電子 | 消費電子 | 電子FPC | 電路板 | 集成電路 | 元宇宙 | 區塊鏈 | NFT數字藏品 | 虛擬貨幣 | 比特幣 | 數字貨幣 | 資産管理 | 保險行業 | 保險科技 | 財産保險 |
